Amazon released technical guidance for Nova Forge users on tuning hyperparameters to specialize large language models on proprietary data while preserving general instruction‑following and reasoning capabilities.
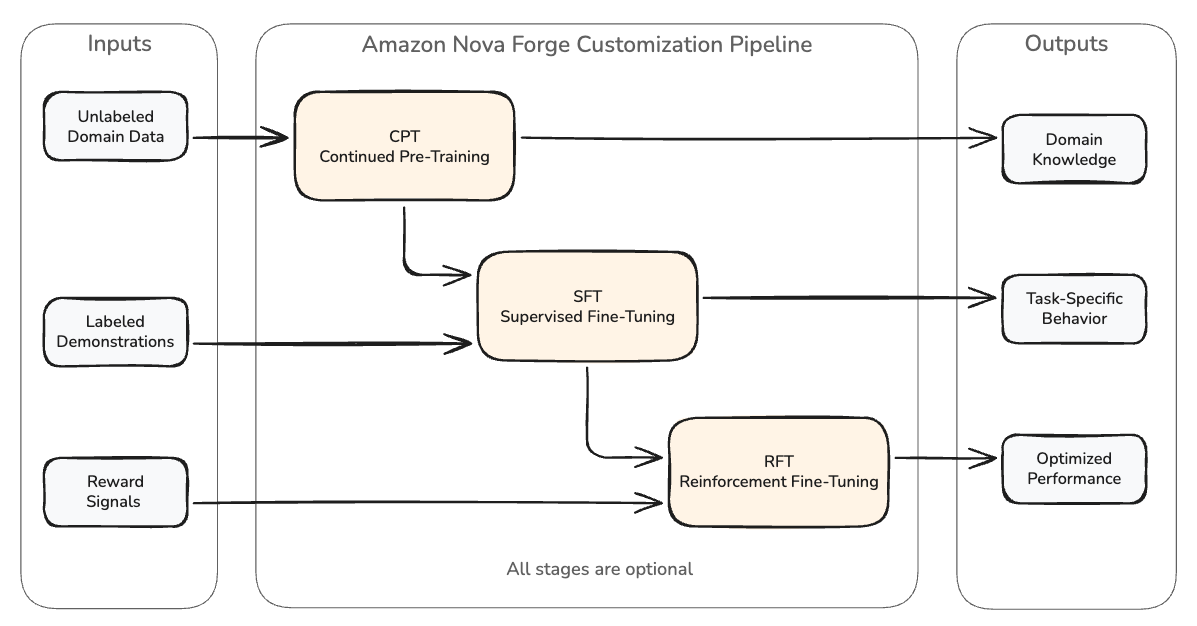
Amazon has published detailed guidance for builders using Amazon Nova Forge on how to tune hyperparameters when customizing large language models for domain‑specific tasks. The guidance explains how to train models on proprietary data and internal processes without degrading core instruction‑following, reasoning, and language abilities, a balance that matters to teams deploying models in production where both accuracy on niche tasks and robustness across broad tasks are required.
Nova Forge supports several features aimed at this balance: starting training from early model checkpoints, mixing customer examples with Amazon Nova‑curated datasets during training, and securely hosting custom models on AWS. A central capability is data mixing, which injects curated general‑purpose data alongside proprietary examples to help preserve the model’s broad behavior; checkpoint selection lets teams control how much of prior alignment and capabilities are retained as customization proceeds.
The guidance situates these capabilities against a common failure mode: fine‑tuning on narrow domain data can cause catastrophic forgetting — loss of instruction following, reasoning, and multi‑turn coherence. That creates a stability‑flexibility tradeoff for builders who need models both specialized and robust. To manage the tradeoff, the post stresses careful hyperparameter tuning because learning rate, data mixing ratio, checkpoint choice, batch size, and training technique interact in ways that can silently undermine a training run. Misconfigured training can destabilize models, erase base capabilities, or simply waste compute.
Practically, the guide flags learning rate as the single most sensitive hyperparameter: set too high it causes overshooting and rapid forgetting; set too low it yields slow convergence and wasted resources. Sensitivity grows when mixing Nova data with proprietary data, and the authors note that deviating from the recommended learning‑rate defaults during data mixing is the most frequent source of instability. The document treats tuning as both art and science, walking builders through customization strategy selection by data and task, configuring influential parameters, and common pitfalls that lead to expensive failed runs.
To reduce risk, Nova Forge provides calibrated service defaults as recommended starting points and recommends monitoring metrics early in training to detect instability. It also advises using checkpoint selection to preserve alignment and beginning experiments from the supplied defaults before making aggressive parameter changes. Following those steps, teams can better retain general model behavior while improving performance on domain‑specific tasks without incurring hidden failures or wasted compute.
Sources
Replies (0)
No replies in this topic yet.