Azercell Telecom and the AWS Generative AI Innovation Center have built a production — ready Azerbaijani large language model on Amazon SageMaker AI to power telecom use cases and a customer — facing chatbot. The collaboration produced a working training framework in six weeks and targets the twin challenges of a morphologically rich language and limited Azerbaijani training data. This approach directly benefits builders working with low-resource, morphologically complex languages by making experimentation and production evaluation faster and cheaper.
Engineering work focused on runtime efficiency and model — context capacity. Kernel — level optimizations on an ml.p5.48xlarge instance produced a 23% increase in training throughput and a 58% reduction in peak GPU memory usage versus the baseline configuration. A custom tokenizer doubled tokens per word-halving tokens per word compared with the English — optimized baseline — effectively fitting twice as much Azerbaijani text into the same context window without changing model size.
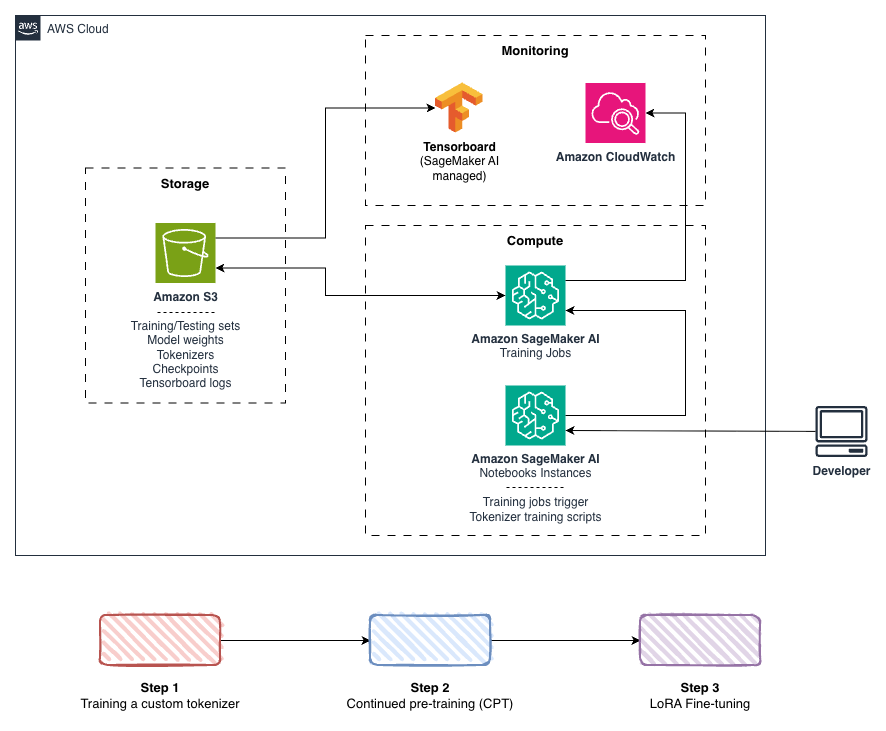
The implementation uses widely adopted open-source components and adapts foundation models to a low-resource language. Core components include PyTorch, Hugging Face Transformers and Liger Kernels. The proof — of-concept used a 1B-parameter foundation model, and the team notes that distributed training will become essential as Azercell scales to larger models and production traffic. Work was organized into a three — stage pipeline so each stage produces artifacts for the next: tokenizer development, continued pretraining (CPT), and supervised fine-tuning with Low — Rank Adaptation (LoRA). That modular structure lets teams optimize stages independently — tokenizer gains immediately improve CPT and fine-tuning, while CPT configurations can be reused across downstream tasks.
Stage details underline those gains. Stage 1 compared three tokenization strategies — baseline English — optimized tokenizers, vocabulary extension, and custom monolingual tokenizers — with the custom monolingual tokenizer halving tokens per word versus the baseline. Stage 2 applied continued pretraining to Llama 3.2 1B using distributed training patterns and Liger Kernel optimizations to enable larger batch sizes and higher throughput. Stage 3 used LoRA to convert the pre-trained model into a conversational assistant while keeping fine-tuning parameter counts low.
Operationally, training ran as Amazon SageMaker AI training jobs launched from SageMaker Unified Studio and executed on freshly provisioned Amazon EC2 instances that terminate after completion, so teams pay only for active compute. Artifacts are stored in Amazon S3, training metrics tracked with TensorBoard in SageMaker, and system metrics captured via Amazon CloudWatch — an integrated stack intended to make iterative experimentation and production scaling more tractable for teams working on low-resource languages.
Sources
Replies (0)
No replies in this topic yet.