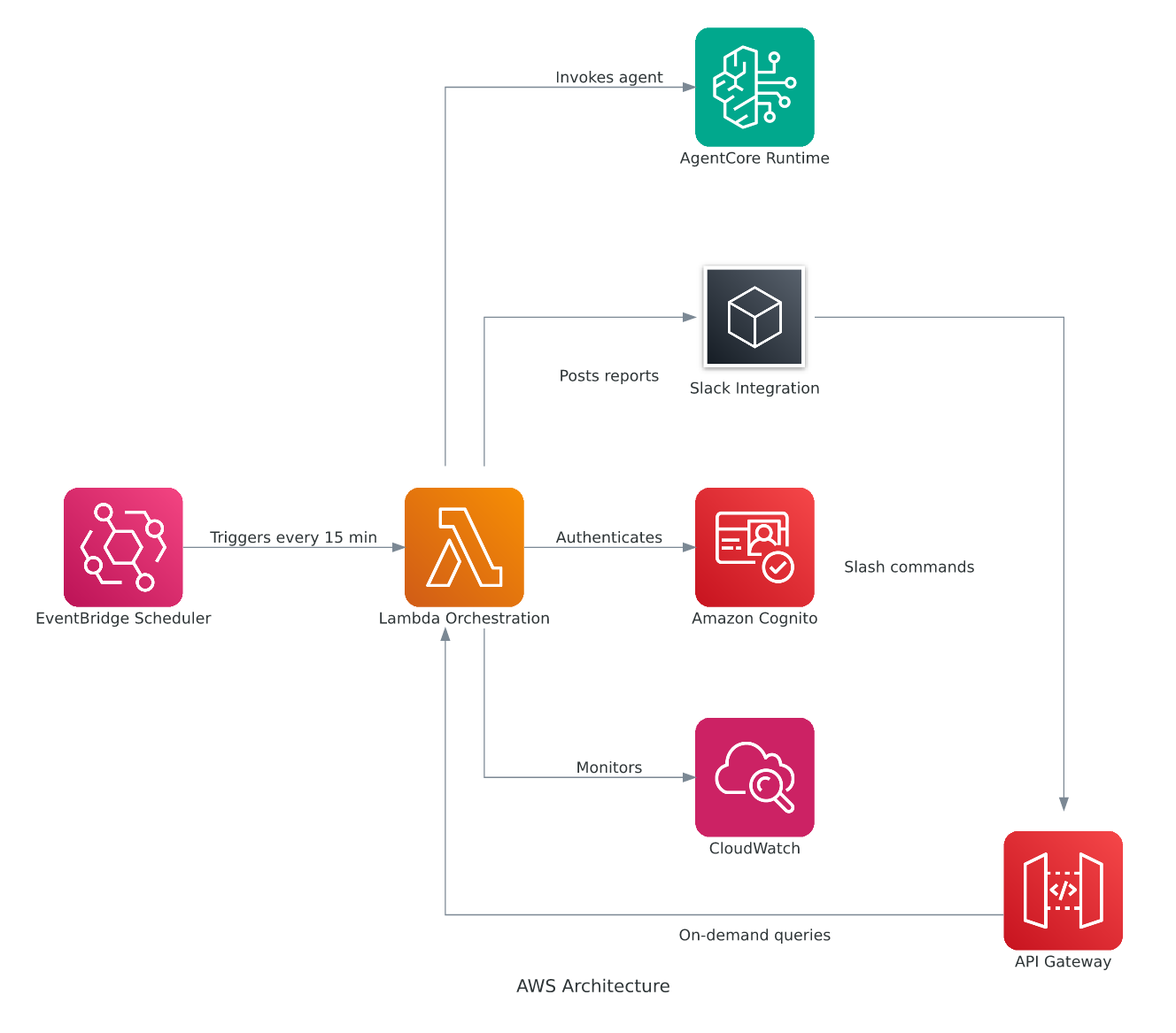
AgentWatch is an ambient monitoring agent that performs recurring infrastructure checks every 15 minutes across multiple AWS accounts, summarizing Amazon CloudWatch metrics, logs and alarms and delivering actionable reports to Slack. It can also respond to natural — language queries about infrastructure state, providing an end-to-end demonstration of behavior rather than a conceptual design. This matters because faster, automated summaries and on-demand answers can reduce the time teams spend chasing alerts and context switching.
The implementation is built on an Amazon Bedrock large language model and deployed with the Bedrock AgentCore Runtime, a secure, serverless hosting environment designed to run AI agents at scale. AgentWatch consolidates telemetry from multiple accounts, processes event streams, and produces concise findings for operators instead of raw dashboards. The post emphasizes a practical walkthrough of code and behavior rather than only high-level architecture.
The walkthrough situates AgentWatch within the ambient agent paradigm: event — driven systems that listen to streams, respond dynamically, and handle multiple events or tasks in parallel. Ambient agents aim to keep continuous watch with minimal human input, surfacing only the most important items for human attention. The authors present this pattern as a way to maintain oversight while minimizing unnecessary interruptions.
The post highlights operational gaps AgentWatch targets: reactive CloudWatch alarms often trigger too late, AWS Lambda errors can accumulate unnoticed, and Amazon EC2 performance degradation may go undetected until customers report problems. Those gaps lead to context switching, manual dashboard checks, and lengthy post-mortems. By continuously observing resources and surfacing prioritized insights, AgentWatch is positioned to shift effort from firefighting toward prevention.
For builders, integrations such as Slack reporting and a natural — language query interface are shown as practical approaches to fold ambient monitoring into DevOps workflows and reduce manual triage and alert fatigue. The authors also explore three human — in-the-loop patterns to retain control while maximizing automation, stressing that deployment requires careful consideration of when agents should notify people and how teams preserve control. The solution is specifically positioned for multi — account AWS environments where event — driven, continuous observation can improve overall operational posture.
Sources
Replies (0)
No replies in this topic yet.