A new how-to shows implementing Recursive Language Models (RLMs) with Amazon Bedrock AgentCore Code Interpreter and the Strands Agents SDK to analyze documents of virtually unlimited size.
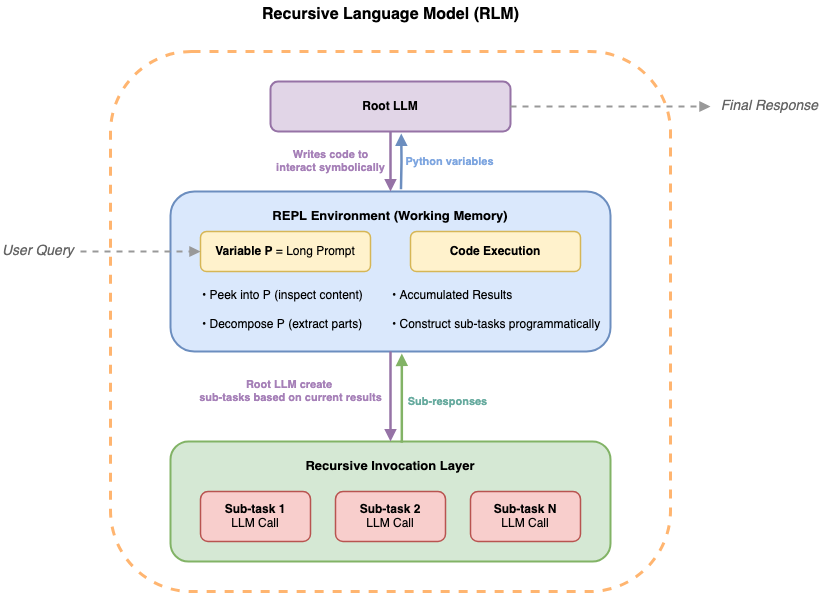
A technical walkthrough demonstrates how to implement Recursive Language Models (RLMs) using Amazon Bedrock AgentCore Code Interpreter together with the Strands Agents SDK to overcome hard context window limits. Instead of attempting to feed long inputs into one model invocation, the root LLM orchestrates iterative analysis by generating code that interacts with the full document stored outside its context window.
Concretely, the pattern runs three cooperating components: a root LLM agent built via the Strands Agents SDK, an AgentCore Code Interpreter session that provides a sandboxed Python runtime with persistent state, and an injected llm_query() helper inside the sandbox that calls Amazon Bedrock for sub‑LLM analysis. The full input document is preloaded as a Python variable in the sandbox, the root agent writes and executes Python to search and slice the data, and intermediate results accumulate as Python variables instead of tokens in the root LLM’s context.
The post frames this approach against the practical limits of context windows: financial analysis workflows often combine annual reports of roughly 300 — 500 pages each plus analyst notes and filings, producing data sets that amount to millions of characters. Directly sending such material either exceeds model limits or triggers the “lost in the middle” attention failure. RLMs, as described by Zhang et al. (arXiv:2512.24601), treat the document as an external environment that the root model manipulates programmatically, which decouples input size from model context.
For builders, the chief consequence is that document size no longer maps directly to the root LLM’s token budget. The root agent focuses on orchestration — issuing search, slice, and control commands — while semantic interpretation of selected chunks is delegated to sub‑LLMs called from within the sandbox. Because sub‑LLM outputs are stored in Python variables in the persistent AgentCore session, those results do not consume the root LLM’s context window and can be iteratively refined across executions.
Architecturally, the AgentCore sandbox must run in PUBLIC network mode so the injected llm_query() can make outbound API calls to Amazon Bedrock. The persistent session state is what enables multi‑step workflows: variables, extracted snippets, and aggregated findings persist across runs so subsequent code executions operate on accumulated state rather than re‑tokenizing the entire source document.
The pattern is pitched for workflows that require iterative, programmatic exploration of large corpora — for example, cross‑year financial comparisons or combined analysis of reports and regulatory filings. It preserves the full document in a controlled execution environment, relies on sub‑LLM calls for semantic tasks, and shifts complexity from prompt engineering to sandbox orchestration and safe API usage, so builders should plan for session management, security posture of PUBLIC mode, and sub‑LLM cost and latency trade‑offs.
Sources
Replies (0)
No replies in this topic yet.