Amazon Finance’s Finance Technology teams built an intelligent regulatory‑response system using Retrieval‑Augmented Generation with Bedrock Knowledge Bases, Amazon OpenSearch Serverless vector storage, and real‑time chat via Claude Sonnet 4.
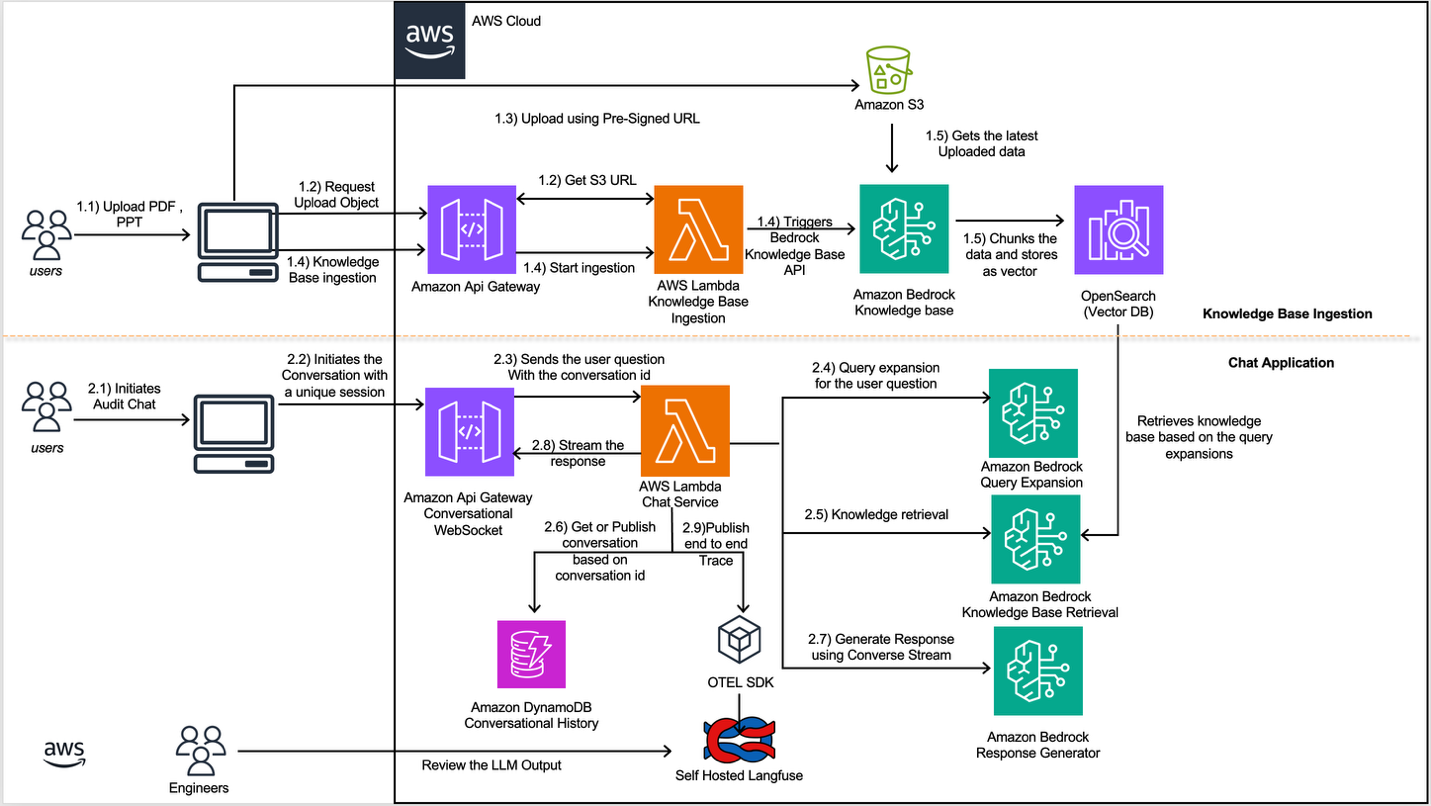
Amazon Finance has deployed an intelligent regulatory‑response automation system on AWS that applies Retrieval‑Augmented Generation (RAG) to synthesize thousands of historical documents and accelerate answers to time‑sensitive regulatory inquiries. The change matters because inquiries span multiple jurisdictions, increase in frequency and complexity, and require scalable, auditable responses assembled under tight deadlines. This system is intended to help Finance Technology (FinTech) teams produce consistent, traceable replies more efficiently.
At the core of the solution, each FinTech team maintains its own Bedrock Knowledge Base populated with that team’s documents and reference materials to limit scope and reduce compliance risk. The architecture pairs those knowledge bases with Amazon OpenSearch Serverless for vector storage and runs real‑time chat using Claude Sonnet 4.5 via the Converse Stream API, forming a concrete RAG pattern tied to vector search and stream‑based LLM calls.
Orchestration and state management are handled with AWS Lambda and Amazon DynamoDB, the former coordinating the pipeline and the latter storing conversation history and multi‑turn interaction state. The ingestion pipeline supports bulk uploads and common file formats — PDF, PPT, Word, CSV-transforms content into embeddings for vector search, and deliberately avoids caching LLM responses or intermediate results because regulatory contexts produce a low cache hit rate.
Operational observability and feedback are built into the stack to detect accuracy drift and provenance issues. OpenTelemetry captures telemetry across retrieval and model calls, while a self‑hosted Langfuse instance provides visibility into model outputs, retrieval provenance, and user interactions. Those tools help surface model hallucinations, flag retrieval of outdated compliance documents, and support continuous iteration on prompts and corpora. The knowledge‑base ingestion flow is automated: after users upload documents, the pipeline extracts and preprocesses content, creates embeddings, and registers them in Bedrock Knowledge Bases for retrieval. That workflow is designed for frequent updates and bulk reingestion so teams can keep domain‑specific precedents and guidance current without manually reindexing thousands of files.
For builders and implementers, the design preserves technical detail and rollout context: it demonstrates a RAG pattern integrated with vector storage and stream‑based LLM calls; it emphasizes per‑team KB ownership to limit scope and compliance exposure; and it highlights observability requirements to guard against accuracy drift. Key design choices — no LLM caching, support for multi‑format ingestion, and integrated telemetry — reflect operational realities when automating regulatory responses and enable continuous improvement of prompts, corpora, and retrieval strategies.
Sources
Replies (0)
No replies in this topic yet.