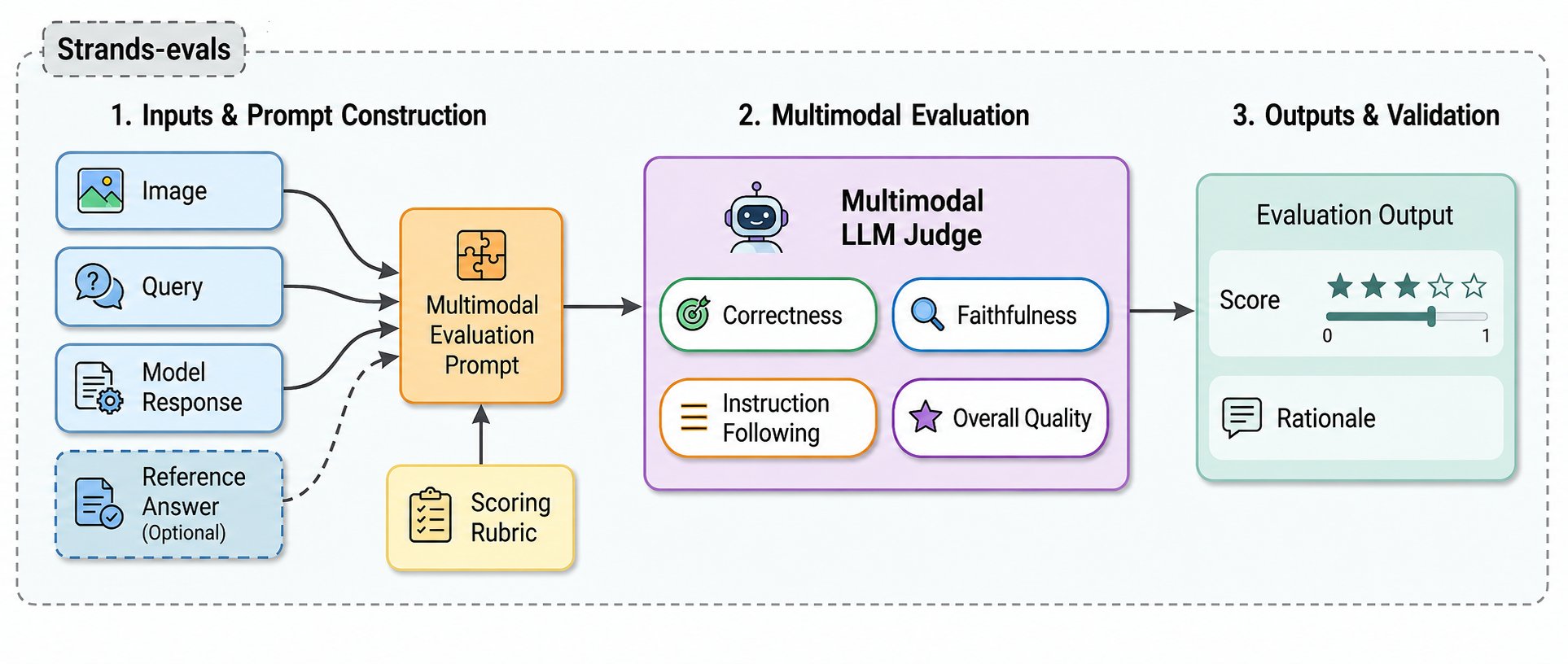
AWS has added four multimodal large‑language‑model (MLLM) evaluators to the Strands Evals SDK to verify that image‑to‑text outputs are grounded in their source images. The new judges — Overall Quality, Correctness, Faithfulness, and Instruction Following — take the image along with the query, the model response, and an optional reference answer and submit them to a multimodal judge model for scoring. This lets teams move beyond text‑only checks and directly test whether responses reflect the visual input.
Each evaluator produces a numeric judgment grounded in the image — either a Likert 1–5 rating or a binary pass/fail-plus a human‑readable reasoning string intended for debugging. The Strands framework constructs a multimodal evaluation prompt, invokes a chosen judge model hosted via Amazon Bedrock, and emits both the numeric score and the rationale so those outputs can be stored in Strands Evals reports for triage and analysis.
The evaluators are designed as drop‑in replacements for text‑only judges in the Strands Evals Case → Experiment → Report workflow and can be plugged into continuous integration (CI) pipelines. That enables automated detection of visual hallucinations, factual errors, and instruction violations early in development rather than relying solely on costly human review or indirect text‑only proxies.
AWS documents practical usage options: the same evaluator can run in reference‑based or reference‑free mode, teams can author custom multimodal rubrics for domain‑specific criteria, and developers choose a judge model on Amazon Bedrock to balance accuracy, cost, and latency. The blog also notes prompt‑design tweaks used in the authors’ experiments that improved alignment between judge outputs and human judgments.
The company also underscores why text‑only judges are inadequate for many image‑grounded tasks: they can miss chart trends not described in text, fail to spot hallucinated products, labels, or people, and misinterpret the intended question or output format. Collapsing these distinct failure modes into a single holistic score can obscure whether the underlying issue is factual, fabricated, or an instruction violation, which complicates targeted fixes.
Practical setup requirements accompany the release: Python 3.10 or later is required, the walkthrough references pip installs for the evaluators and example agents, and users need an AWS account with Amazon Bedrock access plus local AWS credentials configured with the Bedrock InvokeModel permission. The integration is presented as tooling for builders rather than an out‑of‑the‑box managed evaluation service.
AWS positions the multimodal evaluators for teams working on visual shopping, document understanding, and chart analysis that need automated, image‑grounded evaluation at scale. By surfacing both grounded numeric scores and reasoning strings, the new judges aim to make it easier to triage visual errors and iterate on model and prompt fixes without adding human reviewers to every test run.
Sources
Replies (0)
No replies in this topic yet.