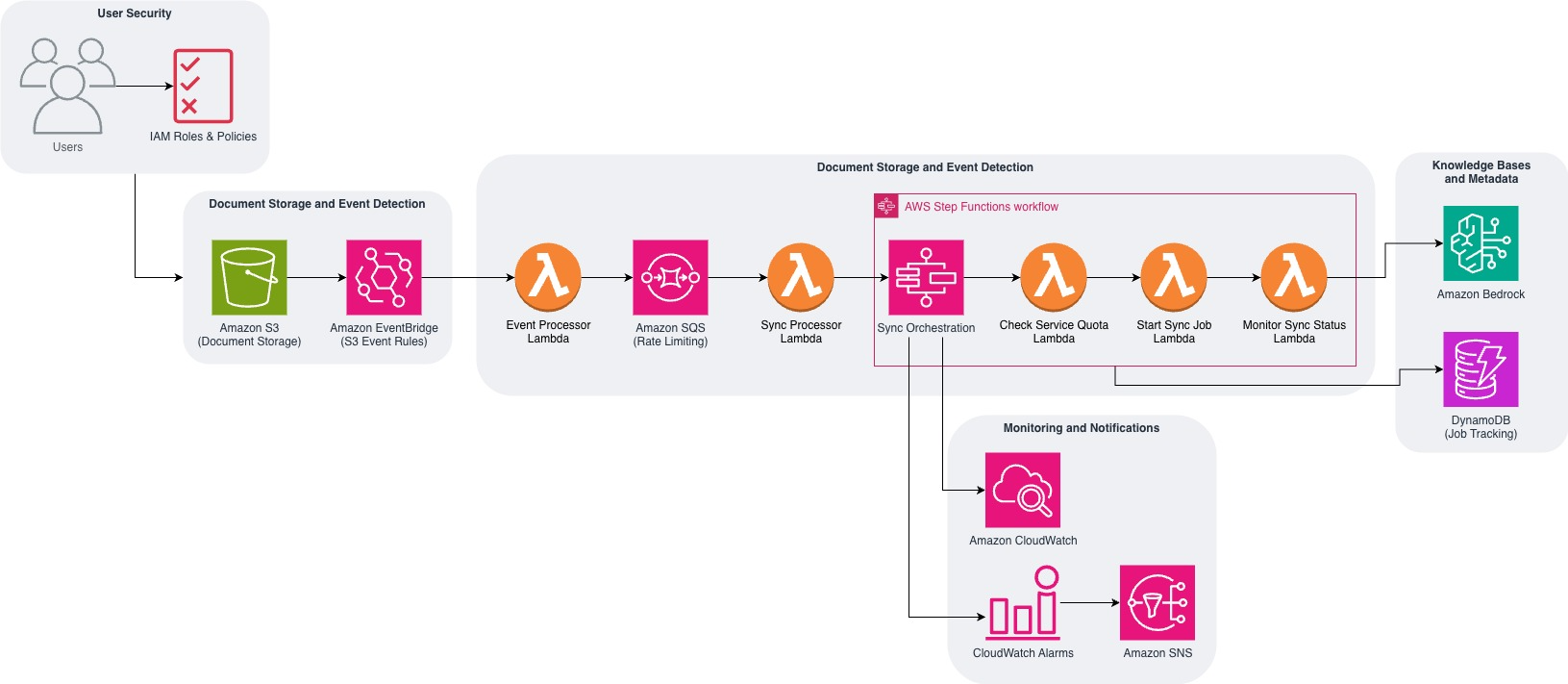
Amazon Web Services has detailed a comprehensive automated synchronization architecture designed to keep Amazon Bedrock Knowledge Bases continuously updated with enterprise data stored in Amazon Simple Storage Service. Providing foundation models and agents with contextual information from private data sources is crucial for delivering relevant and customized responses, but maintaining data freshness introduces significant operational hurdles. Previously, maintaining these knowledge bases required manual synchronization whenever documents or their associated metadata files were added, modified, or deleted within the storage buckets.
The fundamental challenge in automating this data pipeline lies in navigating the strict protective constraints and service quotas implemented by Amazon Bedrock. Organizations cannot simply trigger an update for every file change without overwhelming the system. Specifically, concurrent ingestion jobs are strictly limited to five per AWS account to prevent resource exhaustion, one job per knowledge base for focused processing, and one job per data source to maintain data consistency. Furthermore, the StartIngestionJob application programming interface enforces a rigid rate limit of just 0.1 requests per second, equating to exactly one request every ten seconds in each supported Region.
To circumvent these bottlenecks without requiring manual oversight, the newly documented solution leverages the AWS Serverless Application Model to deploy a fully event — driven, serverless pipeline. The initial phase of this architecture focuses on automated document change detection, utilizing Amazon EventBridge as the primary interceptor. Whenever a file is manipulated in the designated storage bucket, an event is automatically routed to an AWS Lambda function for sequential processing. Instead of immediately pushing the update to the foundation model, the Lambda function intelligently routes a synchronization request to Amazon Simple Queue Service.
Beyond basic event buffering, the architecture relies on additional native services to securely manage the entire synchronization lifecycle and maintain accurate system states. AWS Step Functions are deployed to orchestrate the broader synchronization workflow, moving data smoothly from the buffer to the knowledge base at an acceptable rate. Simultaneously, Amazon DynamoDB is utilized to track job metadata and record specific document changes. During the initial processing phase, the Lambda function extracts vital metadata elements, including the exact file path, the specific type of change, and the timestamp, creating permanent tracking entries in the database for audit purposes.
The immediate consequence of implementing this orchestrated framework is a dramatic reduction in operational overhead and an increase in platform reliability. Engineering teams are no longer forced to build and maintain fragile middleware scripts or deal with delays caused by forgotten manual synchronization tasks. By cleanly abstracting the complex orchestration of data ingestion, organizations can safely deploy intelligent agents into production environments that demand continuous data freshness. While the documented architecture addresses the current technical limitations perfectly, the official documentation notes that Bedrock service quotas and regional limits may evolve over time.
Sources
Replies (0)
No replies in this topic yet.