Enterprises building artificial intelligence agents frequently encounter limitations with managed foundation model services, driving a need for more granular control over performance, data residency, and security integrations. To address these enterprise requirements, Amazon Web Services has detailed a comprehensive architectural methodology combining the open-source Strands Agents SDK with Amazon SageMaker AI. This blueprint allows organizations to retain strict architectural control over how and where inference happens, ensuring compliance and precise infrastructure placement while still benefiting from a managed operational layer.
The deployment workflow utilizes Amazon SageMaker JumpStart as a foundational machine learning hub where engineering teams can evaluate and select foundation models based on predefined quality and responsibility metrics. Rather than relying solely on opaque managed interfaces, developers can deploy both custom fine-tuned models and open-source alternatives, such as Llama or Mistral, directly onto dedicated SageMaker AI endpoints. The source documentation specifically highlights the ability to use models like Qwen3 4B and Qwen3 8B, noting that any model utilized with the Strands Agents SDK must support OpenAI — compatible chat completion application programming interfaces.
Once the underlying infrastructure is provisioned, developers utilize the Strands Agents SDK to construct the actual autonomous agents. This open-source software development kit takes a model — driven approach, allowing teams to bind a foundation model, a system prompt, and specific operational tools together with minimal code. The framework scales seamlessly from local development environments to full production deployments and includes a dedicated tools library designed to accelerate the creation of agents tailored to specific business use cases. While SageMaker AI provides direct infrastructure control, the SDK also maintains compatibility with Amazon Bedrock inference profiles, such as the Claude 4.
A primary advantage of utilizing SageMaker AI models within this architecture is the profound level of infrastructure control it grants to enterprise engineering teams. Organizations with strict latency service — level agreements or specialized hardware requirements can explicitly manage compute instances, networking configurations, and scaling policies. Furthermore, this approach enables precise cost forecasting and optimization for high-volume workloads. By leveraging dedicated endpoints, companies can right — size their compute resources and take advantage of AWS spot pricing or reserved instances, avoiding the unpredictable billing cycles sometimes associated with strictly consumption — based managed services.
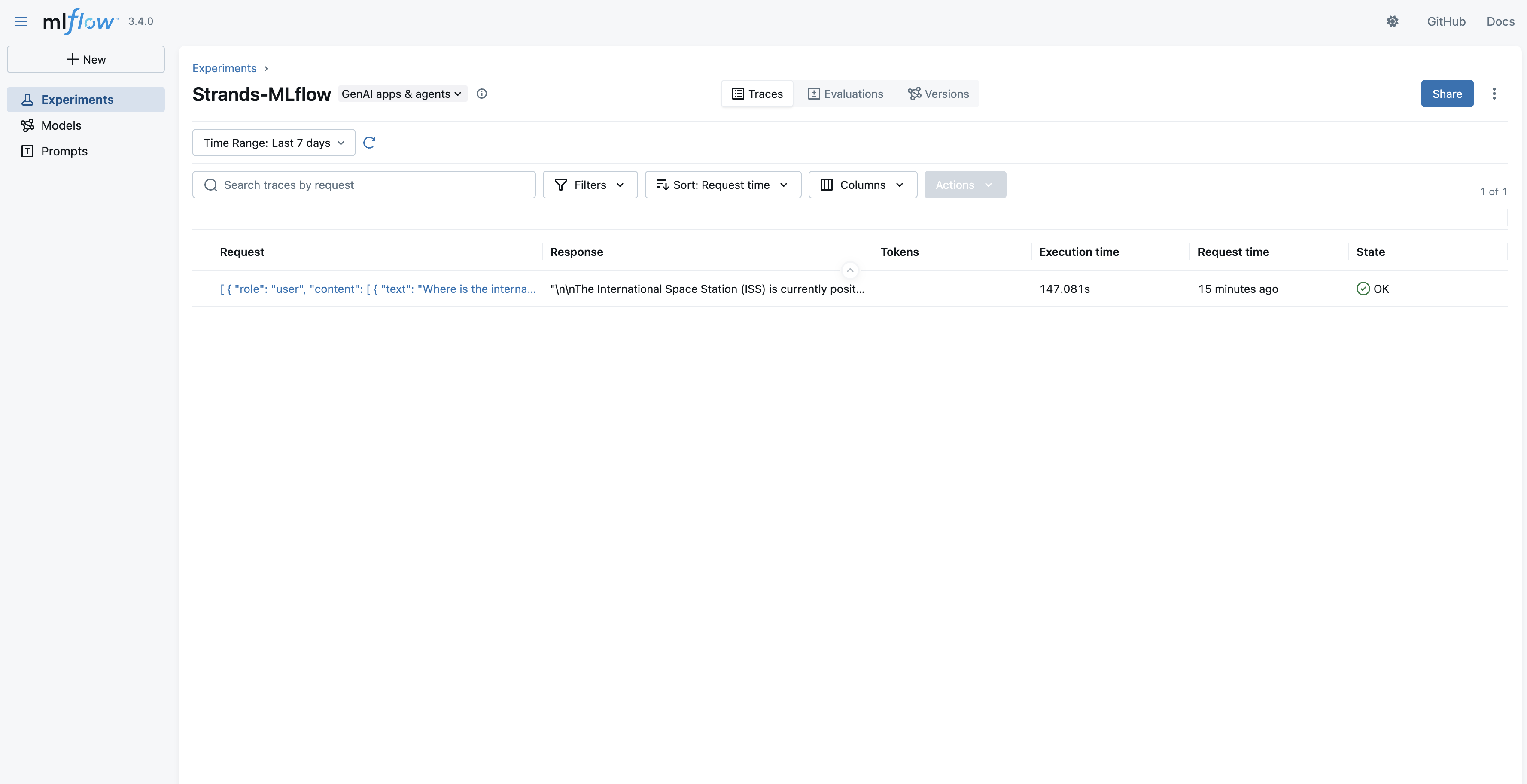
To ensure production — grade reliability, the architecture integrates SageMaker AI MLflow to provide advanced machine learning operations capabilities. This managed service streamlines the entire lifecycle of the agent through rigorous experiment tracking, model versioning, and deployment management. Specifically, it enables continuous agent tracing and observability, moving development beyond experimental prototyping. Engineering teams can implement sophisticated A/B testing across multiple model variants simultaneously, utilizing concrete MLflow metrics to evaluate agent performance and continuously improve the system on infrastructure they exclusively control.
Sources
Replies (0)
No replies in this topic yet.