AWS introduced a new solution for Amazon Bedrock, allowing the implementation of corporate memory using Amazon Neptune and Mem0.
Amazon Web Services (AWS) introduced a solution for implementing corporate memory in the Amazon Bedrock service, using Amazon Neptune and Mem0. This integration is designed to provide AI agents with stable and company-specific context, allowing them to learn and adapt over multiple interactions. One of the first to apply this technology was TrendMicro, which integrated it into its chat — bot Trend’s Companion. This gave customers the ability to interact with information through natural, conversational dialogues.
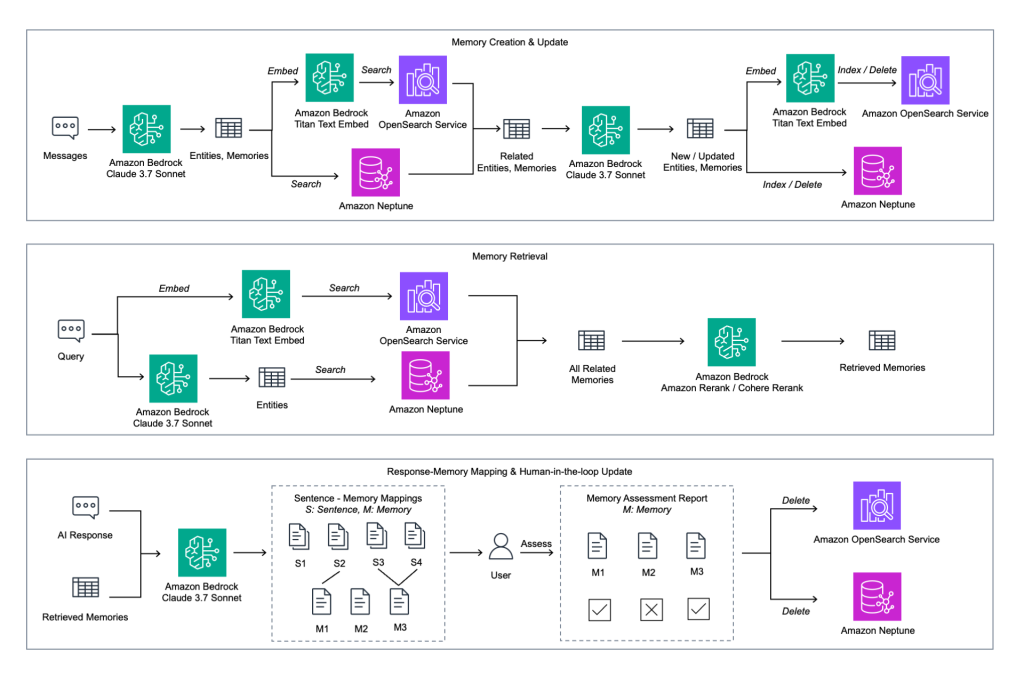
At the core of the new architecture lies a combination of key AWS services. Amazon Neptune serves to store the corporate knowledge graph, containing information about internal connections, processes, and data, which ensures accurate and structured retrieval. Mem0 manages both short-term memory for current dialogues and long-term memory, preserving persistent knowledge across sessions. Amazon Bedrock coordinates the work of AI agents, integrating with Neptune and Mem0 to extract and utilize contextual knowledge in the process of generating responses.
This solution aims to address key challenges of corporate AI chat bots: the need to preserve conversation history for continuity, scalable access to corporate knowledge, and ensuring the relevance, security, and accuracy of memory. It is designed to provide personalized and context — oriented support. The main objective was to integrate long-term memory for organizational knowledge with short-term memory for current conversations, which promotes knowledge sharing across the entire company. This approach significantly improves the user experience, allowing chat — bots to retrieve relevant history, extract structured corporate knowledge, and form accurate, context-rich responses. The architecture also utilizes Amazon OpenSearch Service for semantic flexibility and Amazon Neptune for structural precision, enabling the chat — bot to generate highly relevant responses.
The process of creating and updating memory begins with capturing user messages and extracting entities, relationships, and potential memories using the Claude model in Amazon Bedrock. These data are then embedded via Amazon Bedrock Titan Text Embed and used for searching in Amazon OpenSearch Service and Amazon Neptune. Identified entities and memories are extracted, updated with the relevant model, and then re-embedded and indexed back into OpenSearch and Neptune. This ensures continuous updating and relevance of the knowledge base.
The system also integrates a human-in-the-loop feedback mechanism (human — in-the-loop). For each AI-generated response, the system matches propositions with the memories used, generating a report on their evaluation. Users have the option to approve or reject these matches. Approved memories remain in the knowledge base, while rejected ones are removed from OpenSearch Service and Neptune. This approach ensures that only verified and reliable knowledge is retained, constantly improving memory accuracy and giving corporate clients direct influence over the refinement of their AI systems' knowledge.