AWS has introduced a new solution for creating a scalable and cost-effective audio transcription pipeline. It is based on the open multilingual NVIDIA Parakeet — TDT-0.
AWS has introduced a new solution for creating a scalable and cost-effective pipeline for multilingual audio transcription, aimed at significantly reducing costs for large-scale transcription. This innovative offering is based on the use of the open NVIDIA Parakeet — TDT-0.6B-v3 model in combination with key AWS services such as AWS Batch and Amazon S3. The Parakeet — TDT-0.6B-v3 model, expected to be released in August 2025, is fully open-source and supports numerous languages.
the Word Error Rate (WER) is 6.34% under ideal conditions and 11.66% at a signal-to-noise ratio of 0 dB. The model is capable of automatically detecting and processing 25 European languages, including Russian and Ukrainian. The pipeline is deployed using AWS Batch on powerful GPU-accelerated Amazon EC2 instances (e.g., G6, G5, or G4dn), requiring a minimum of 4 GB of video memory, and allows processing audio files up to three hours in duration.
The solution is aimed at organizations dealing with ever-increasing volumes of media data: from archiving extensive libraries and analyzing call center recordings to preparing training data for AI systems and creating video subtitles. With significant data growth, traditional managed Automatic Speech Recognition (ASR) services often become a limiting factor due to high costs. The proposed AWS architecture provides substantial cost reduction — down to fractions of a cent per hour of audio. This is achieved through the use of Amazon EC2 Spot instances and buffered streaming inference, as well as the pipeline's ability to scale to zero during idle periods, minimizing expenses and paying only for the actual compute resource usage time.
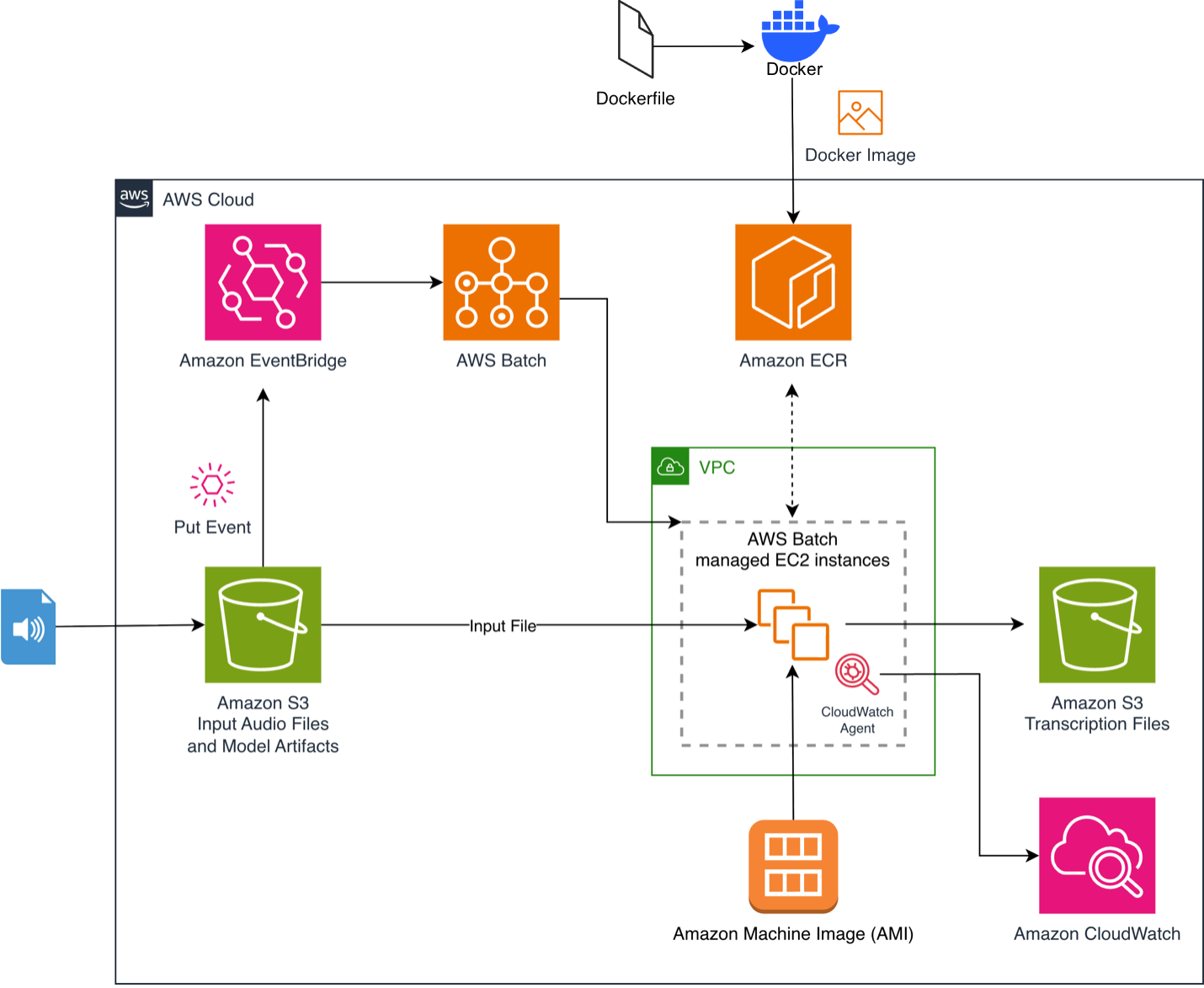
For developers, the pipeline automatically starts when an audio file is uploaded to a specified Amazon S3 bucket. This action triggers an Amazon EventBridge rule that directs the processing job to AWS Batch. AWS Batch then dynamically allocates the necessary GPU resources, after which a container image with the pre-loaded Parakeet — TDT model from Amazon Elastic Container Registry (ECR) performs the transcription. The result — a JSON transcript with timestamps — is saved in the output S3 bucket. Developers benefit from using an open-source model and a ready-made, inference-optimized container image that pre-caches the Parakeet — TDT-0.6B-v3 model during the build phase. This approach eliminates model loading delays during runtime and simplifies integration, allowing developers to focus on building applications rather than the complexities of managing multiple models for different languages.