A China — based research team published AntAngelMed on ModelScope: An open-source medical language model built as a Mixture — of-Experts (MoE) with 103B parameters and a 1/32 activation ratio, inheriting Ling-flash-2.
A research team in China has published AntAngelMed on ModelScope, releasing model artifacts and technical documentation for community use. The model is presented as an open-source medical language model intended for clinical and domain — specific work; the team highlights design details, training stages, and inference optimizations to help builders and researchers reproduce and extend the work. This release matters because AntAngelMed aims to lower active — parameter compute costs and handle document — level clinical contexts, which could change deployment trade — offs for medical AI systems.
Architecturally, AntAngelMed is a Mixture — of-Experts (MoE) model with 103 billion total parameters and a 1/32 activation ratio, meaning roughly 6.1 billion parameters are active during each inference. The model builds on a Ling-flash-2.0 checkpoint and incorporates refinements including expert — granularity tuning, a shared — expert ratio, attention — balance mechanisms, sigmoid routing without auxiliary loss, an MTP layer, QK — Norm, and Partial — RoPE.
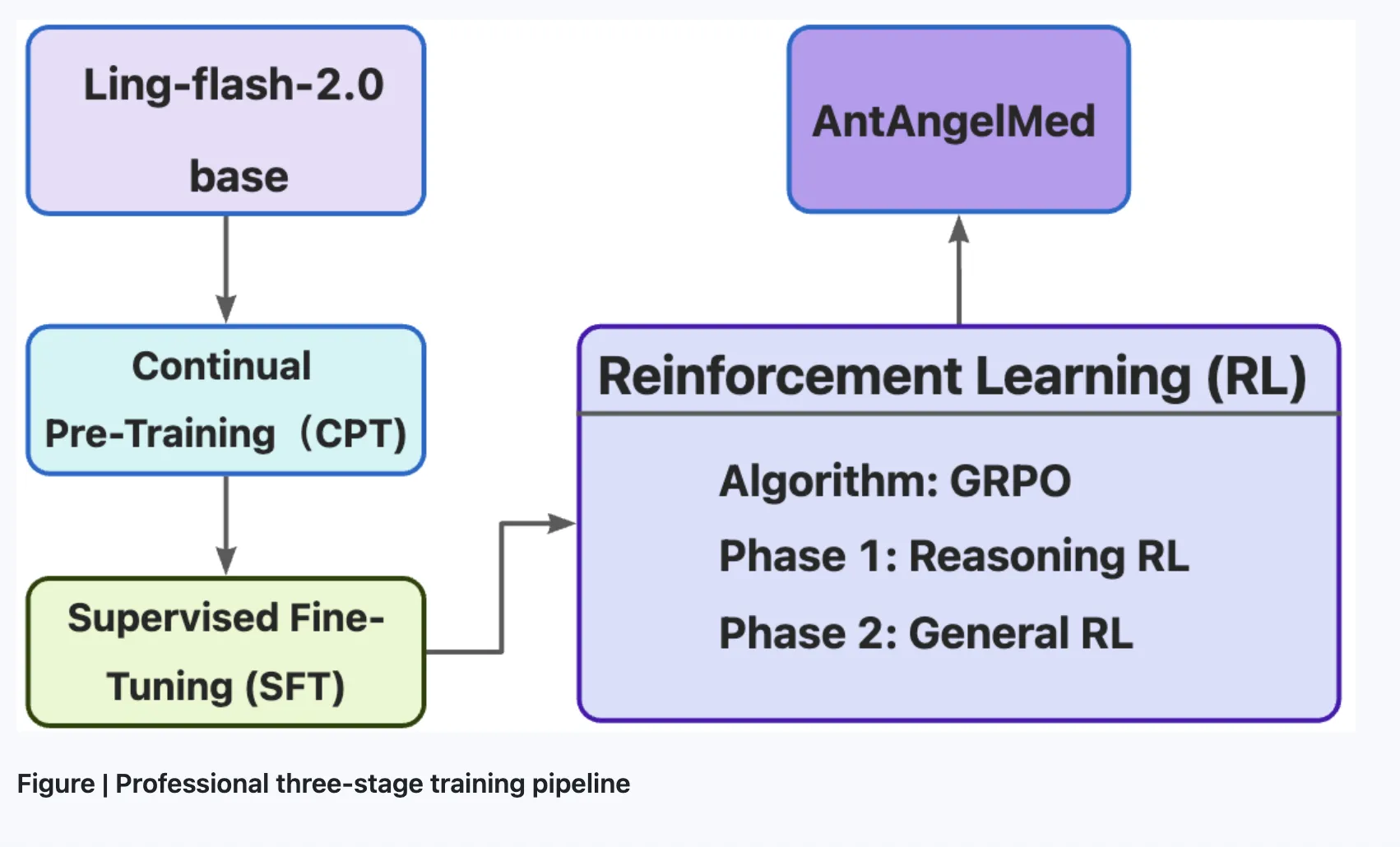
The team describes a three — stage training pipeline. Stage one applies continual pretraining on large — scale medical corpora — encyclopedias, web text, and academic publications — starting from the Ling-flash-2.0 checkpoint. Stage two performs supervised fine-tuning on multi — source instruction data that mixes general reasoning tasks with medical scenarios. Stage three uses reinforcement learning with GRPO and task-specific reward models to encourage empathy, structured clinical responses, safety boundaries, and evidence — based reasoning.
On inference, the team reports AntAngelMed exceeds 200 tokens per second on H20 hardware, roughly three times the throughput of a 36B-parameter dense model in their comparisons. With YaRN extrapolation, the model supports a 128K context length for full clinical documents and extended histories. The authors also released an FP8-quantized variant and show that, when combined with EAGLE3 speculative decoding at concurrency 32, benchmark throughput proxies increase substantially (HumanEval +71%, GSM8K +45%, Math-500 +94%).
For builders, the concrete implications are lower active — parameter compute costs and longer context handling that suit document — level medical workflows and multi — turn dialogues. The MoE design is presented as delivering roughly the performance of a 40B dense model while activating far fewer parameters, which can reduce inference cost and enable different deployment footprints.
The team notes benchmark gains on coding and math proxies but cautions that those results are proxies for general reasoning rather than clinical safety or efficacy. They advise that groups integrating AntAngelMed perform dedicated medical — safety, hallucination, and clinical — efficacy evaluations before production use. Documentation accompanying the release describes the design choices, training stages, and inference optimizations to support reproducibility and further research.
Sources
Replies (0)
No replies in this topic yet.