Cohere released Command A+, an open‑source 218B sparse Mixture‑of‑Experts decoder model under Apache 2.0 that consolidates four Command A variants and offers NVFP4 W4A4 quantization enabling single‑B200 or 2×H100 deployments.
Cohere has published Command A+, a 218 billion‑parameter sparse Mixture‑of‑Experts (MoE) decoder model under an Apache 2.0 license that merges the capabilities of four prior variants — Command A, Command A Reasoning, Command A Vision, and Command A Translate — into a single release aimed at reasoning, retrieval‑augmented generation, multimodal document processing and tool‑enabled agents. The unified release matters because it offers a 25B active‑compute footprint while lowering GPU requirements for many enterprise and on‑prem deployments.
Architecturally, Command A+ is a decoder‑only sparse MoE transformer with 218B total parameters and roughly 25B active parameters at inference. The model uses 128 experts with 8 experts active per token plus a shared expert applied to all tokens, interleaves sliding‑window attention layers (with Rotational Positional Embeddings) and global attention layers in a 3:1 ratio, supports a 128K input context and a 64K max generation length, and was trained using a fully dropless MoE approach with a token‑choice router implemented as a normalized sigmoid over top‑k expert logits.
Cohere published three quantization and precision options with stated minimum GPU requirements: BF16 requires 4× B200 or 8× H100; FP8 requires 2× B200 or 4× H100; and the recommended W4A4 path runs on a single B200 or 2× H100. The W4A4 option uses NVFP4 4‑bit weights/activations with two‑level scaling applied to experts only, while the attention path—Q/K/V/O projections, KV cache and attention compute — remains at higher precision. Cohere also applied Quantization‑Aware Distillation (QAD) in post‑training to reduce quality gaps from aggressive quantization.
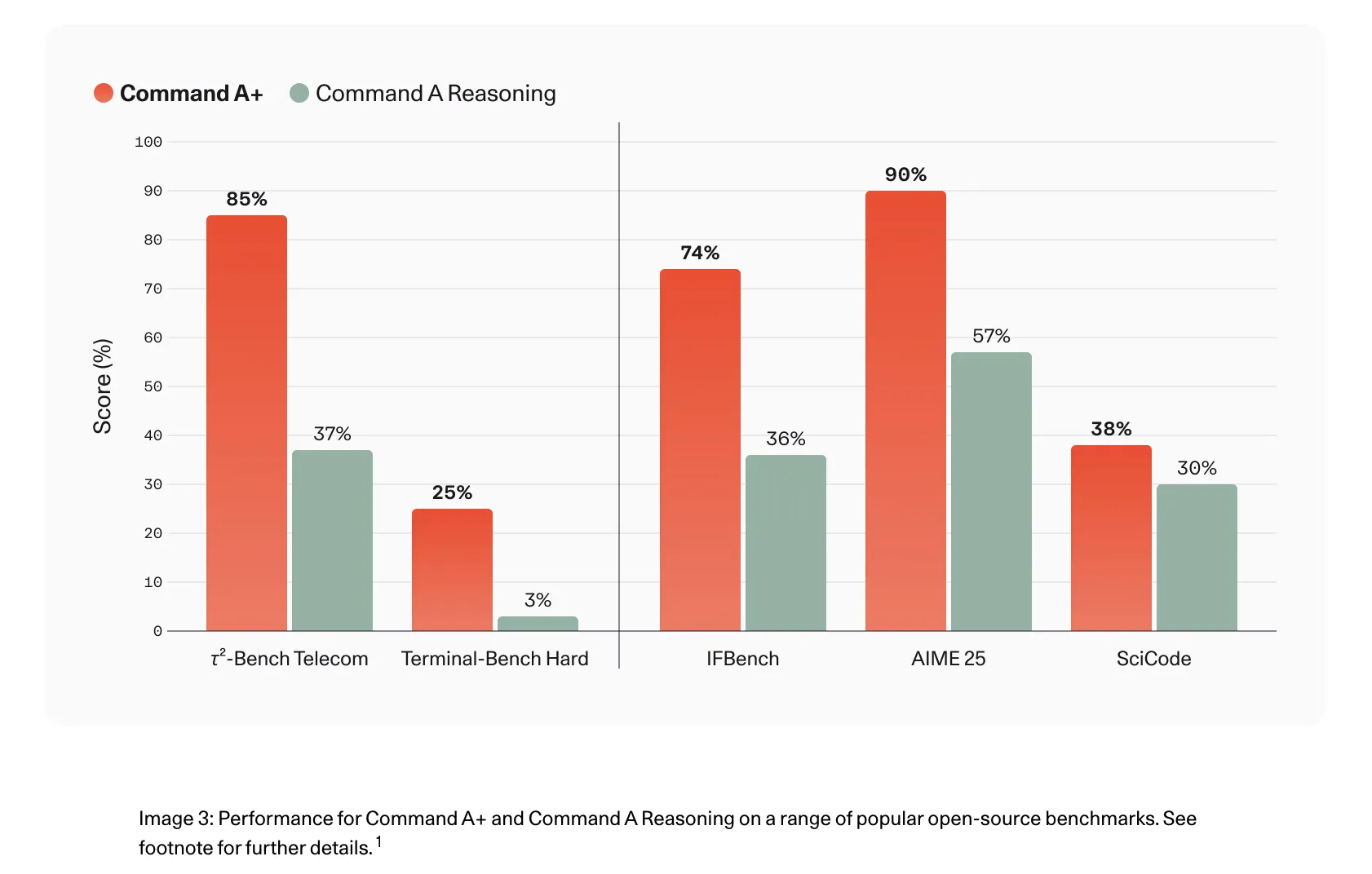
On benchmarks and internal evaluations, Command A+ shows substantial gains versus the prior Command A family. τ²‑Bench Telecom scores rose from 37% to 85% compared with Command A Reasoning, and Terminal‑Bench Hard agentic coding moved from 3% to 25%. Internal LLM‑as‑a‑judge tests reported a 20% improvement in Agentic QA accuracy, a 32% uplift in spreadsheet analysis quality, and memory‑usage quality increasing from 39% to 54%. Multimodal and math reasoning metrics likewise improved across MMMU, MathVista and CharXiv.
Quantization and architectural optimizations yield meaningful throughput and latency benefits: up to 63% higher output tokens per second and up to a 17% reduction in time‑to‑first‑token at equal quantization and concurrency. Cohere attributes roughly a 47% speed boost and a 13% latency reduction to the W4A4 path alone, and it additionally optimized speculative decoding for MoE to improve real‑world agentic responsiveness.
For builders, the combination of MoE sparsity, NVFP4 W4A4 quantization and QAD makes a 25B active‑compute model accessible with a reduced GPU footprint and cost, enabling enterprise agents and RAG systems to run on fewer GPUs. The 128K context window, multimodal input support and Apache 2.0 licensing make both on‑prem and cloud deployments feasible, but teams should plan capacity and latency tradeoffs around the attention path and KV cache, which remain at higher precision.
Sources
Replies (0)
No replies in this topic yet.