In a May 8, 2026 engineering post the DeepSeek‑V4 authors argue that the model’s 1 million‑token context window is primarily an inference‑systems problem rather than only a modeling achievement. Their bring‑up work on NVIDIA HGX B200 shows that how inference engines implement V4’s new attention and caching choices drives real‑world capacity and throughput; the practical takeaway is that serving infrastructure must be rethought to realize V4’s long‑context benefits.
DeepSeek‑V4 attains the million‑token window through a hybrid attention design that compresses the token axis before key‑value (KV) storage, combines compressed and local attention paths, and changes prefix reuse behavior. The post highlights Compressed Sparse Attention (CSA), Heavily Compressed Attention (HCA) and Sliding Window Attention (SWA) as the serving‑relevant elements; other model changes — Manifold‑Constrained Hyper‑Connections (mHC) and Muon optimizer choices — are noted but treated as out of scope for the serving analysis.
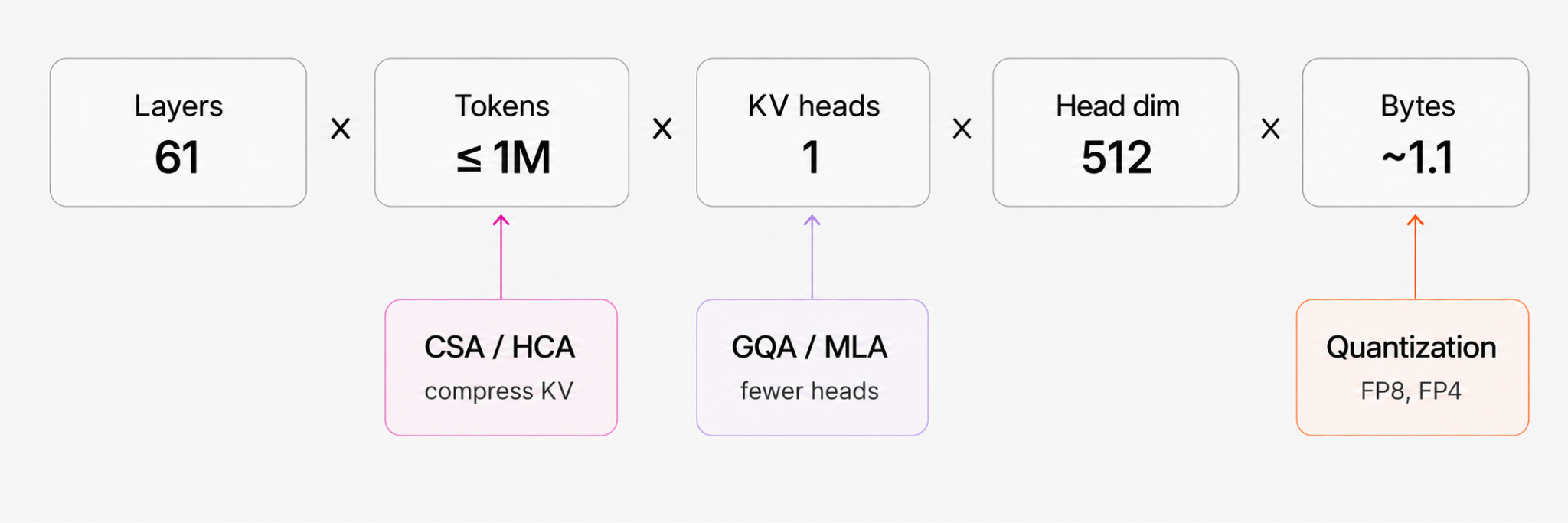
The authors underline why this shift matters by spelling out how autoregressive inference KV cache scales: KV cache ∝ layers × tokens × kv_heads × head_dim × bytes. Prior architecture changes targeted different terms of that product — Group Query Attention (GQA) and Multi‑Head Latent Attention (MLA) reduce head‑count or compress into latents, while FP8/MXFP4 reduce bytes — but V4’s distinct lever is token‑axis compression, which reduces the number of KV entries to store and scan during attention.
Concrete HGX B200 measurements illustrate the systems tradeoffs. A naive full‑SWA implementation actually increased per‑token KV occupancy to about 3.8 KB per token versus roughly 3.4 KB per token on the team’s V3 path because the engine retained the complete sliding‑window state. The primary practical win came from cache‑policy changes: by keeping only the SWA states most likely to be reused, a single HGX B200 node’s KV capacity rose from roughly 1.2M tokens to about 3.7M tokens with minimal code changes.
The post frames a clear operational implication for builders: V4’s architectural savings only convert to throughput and concurrency if the inference engine manages cache layouts, local state recovery, batching and endpoint profiles to match serving economics. Long‑context inference on Blackwell‑class hardware depends on keeping sufficient KV resident for concurrency while preserving memory bandwidth for decode; realized capacity therefore hinges on how the engine stores, recomputes and evicts state and on kernel and endpoint maturity.
Sources
Replies (0)
No replies in this topic yet.