EAGLE 3.1 was released in late May 2026 by the EAGLE, vLLM and TorchSpec teams as a focused reliability update to the EAGLE speculative decoding family. The release addresses a production instability that shortened acceptance lengths and destabilized outputs across different chat templates, long‑context inputs, and out‑of‑distribution system prompts — problems that had reduced the practical speedups speculative decoding could deliver in deployed systems. The change restores speculative decoding’s effectiveness for real‑world serving workloads.
Speculative decoding pairs a small, fast drafter model that proposes several tokens with a larger target model that verifies those proposals in parallel: accepted tokens accelerate inference while rejections fall back to the larger model. In deployed settings the drafter’s proposals became progressively less useful as speculation depth increased, producing shorter acceptance runs and erratic outputs that cut into throughput and reliability.
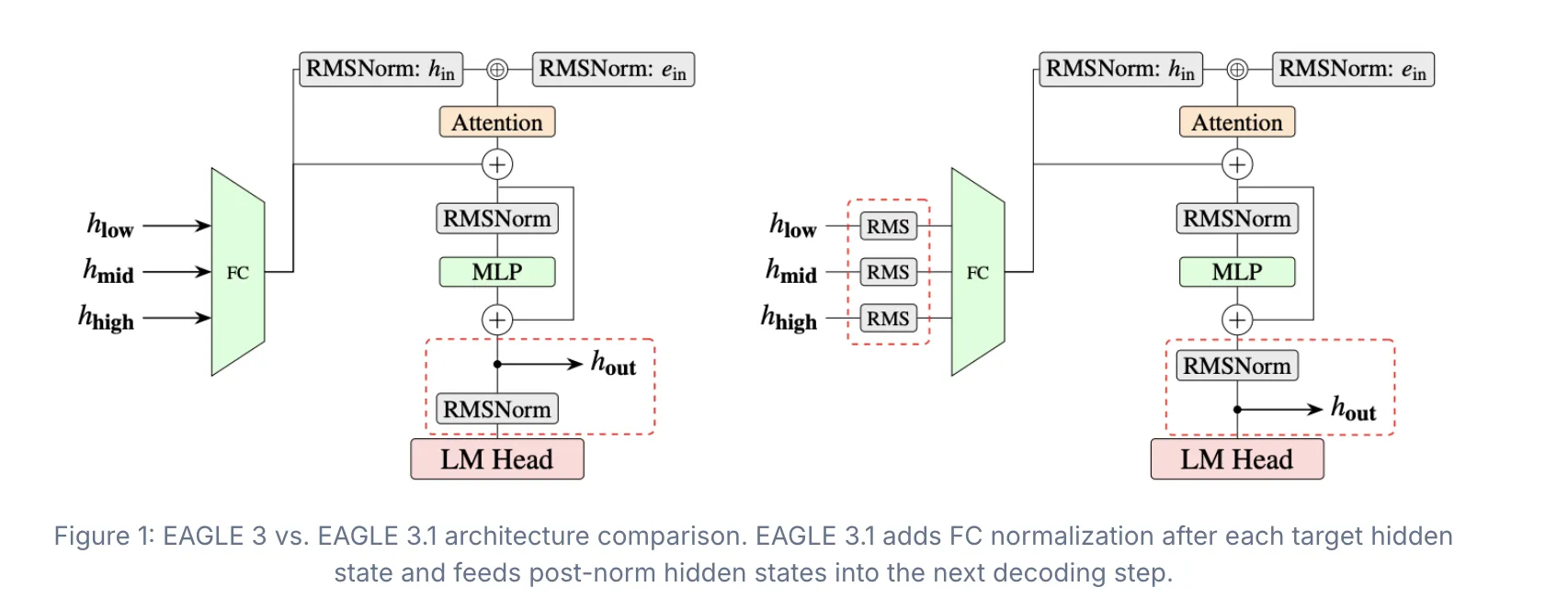
The teams traced this fragility to a phenomenon they call attention drift: as speculation depth grows, the drafter shifts its attention away from sink tokens and back toward its own generated tokens. Two technical causes were identified. First, the fused input representation feeding the drafter became increasingly imbalanced so that higher‑layer target hidden states dominated the drafter input. Second, an unnormalized residual path let hidden‑state magnitudes grow without bound across speculation steps, amplifying the drafter’s tendency to attend to its own outputs.
EAGLE 3.1 implements two architectural mitigations to stop attention drift. It adds FC (fully connected) normalization after each target hidden state and before the final fully connected layer to keep hidden‑state magnitudes bounded. It also feeds post‑norm hidden states back into the next decoding step, converting the drafter from an appended stack of layers into a more recursive decoder that preserves stable state between steps. Together these changes reduce the internal imbalances and uncontrolled growth that caused drift.
Benchmarks show several practical improvements. The update yields better training‑time to inference‑time extrapolation, stronger robustness on long‑context workloads, greater resilience to variations in chat templates and system prompts, and more stable acceptance lengths across serving environments. In long‑context scenarios, EAGLE 3.1 achieves up to 2× longer acceptance length compared with EAGLE 3, directly extending the effective speculation depth for many workloads.
To accelerate adoption, TorchSpec now provides efficient training support for EAGLE 3.1 and future speculative‑decoding experiments, lowering training overhead and simplifying iteration. vLLM integrates EAGLE 3.1 as a configuration‑driven, backward‑compatible extension of the existing EAGLE 3 implementation, including the FC normalization and post‑norm feedback and removing hardcoded target‑hidden‑state assumptions. The teams also trained and open‑sourced an EAGLE 3.1 draft model for Kimi K2.6 on HuggingFace as a deployment example that plugs into vLLM’s speculative‑decoding code path.
Sources
Replies (0)
No replies in this topic yet.