Published guidance for builders who need predictable, time‑bound GPU capacity for ML workloads, comparing on‑demand, Spot, and EC2 Capacity Blocks for ML reservation modes.
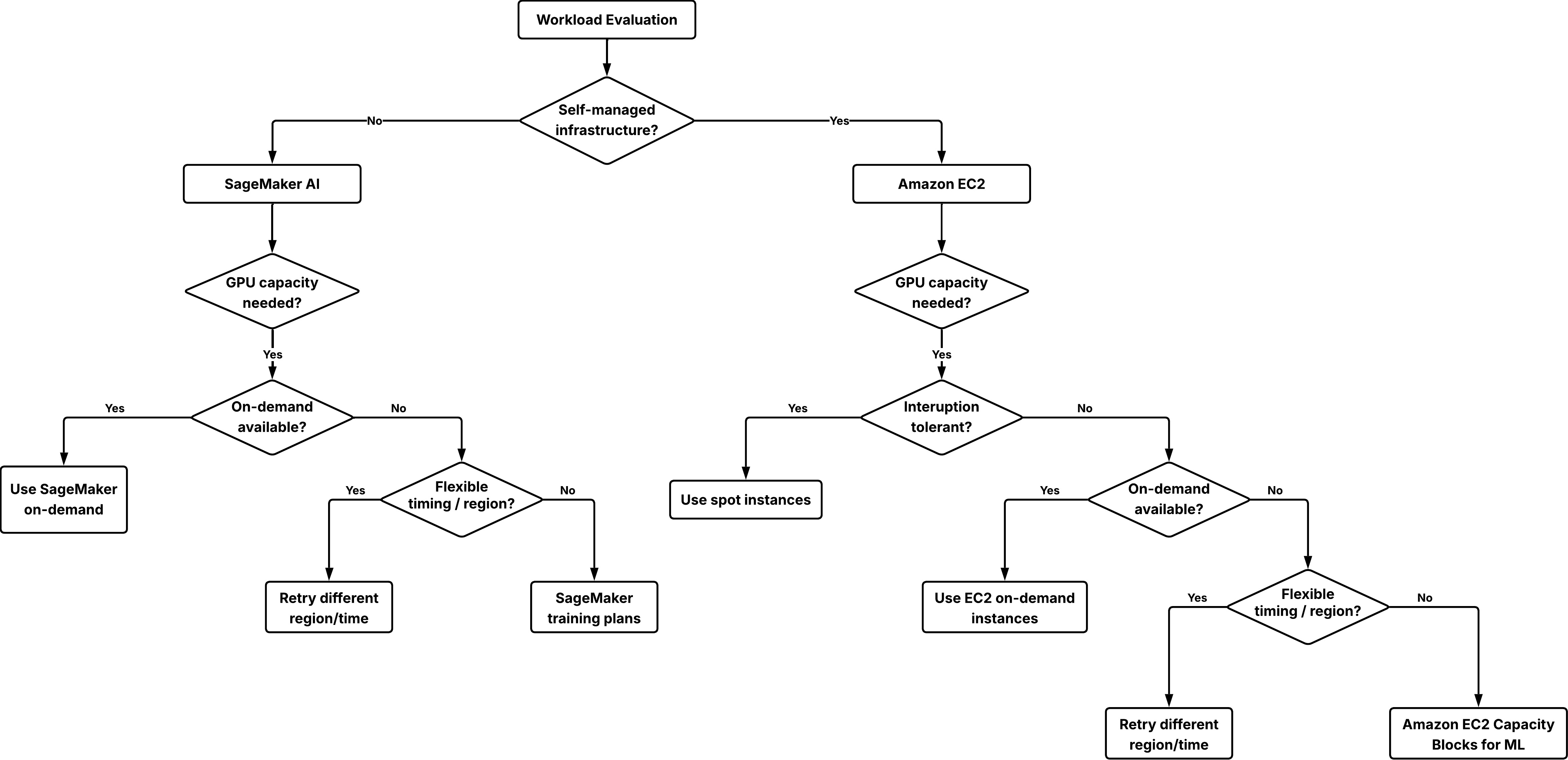
Amazon EC2 Capacity Blocks for ML have been documented as a short‑term GPU reservation mechanism aimed at teams that need predictable, time‑bound capacity for finite ML tasks such as load testing, model validation, instructor‑led workshops, or preparing inference capacity before a release. The guidance explains practical configuration options, trade‑offs and limits so engineering teams can plan around availability constraints rather than relying on ad hoc instance launches. This matters because predictable access and known pricing reduce the risk of missed deadlines or failed demos when GPU capacity is scarce.
The post contrasts three short‑term GPU access modes. On‑demand instances provide immediate starts when capacity exists but availability fluctuates by region and demand, and there is no guarantee of reacquiring the same capacity later. Spot instances can reduce GPU costs by up to 90% but are interruptible, making them suitable only for workloads that can checkpoint and restart. EC2 Capacity Blocks for ML are presented as a middle ground that offers reservation guarantees and predictable pricing for finite windows.
EC2 Capacity Blocks for ML are self‑service reservations that let teams reserve GPU instance capacity for a defined window and claim the instances during that period. A start time may be set up to eight weeks in advance. Duration options are 1–14 days in 1‑day increments and 15–182 days in 7‑day increments. Each block can be configured for up to 64 instances. Organizations can place up to 256 instances across multiple Capacity Blocks on a given date, a ceiling that requires a minimum of four blocks; blocks may run concurrently to reach that limit.
The guidance notes a 40 — 50% discounted rate for Capacity Blocks compared with on‑demand pricing, positioning them as both a predictability and cost improvement for short commitments. Capacity Blocks apply to workloads running directly on EC2, where teams manage the operating system, networking and orchestration layers. For customers who prefer a managed training workflow instead of managing EC2 instances themselves, Amazon SageMaker training plans are highlighted as an alternative path without prescribing specific plan terms.
The post explains why conventional on‑demand capacity reservations (ODCRs) are often a poor fit for short, exploratory use: ODCRs target planned steady‑state workloads, P‑type GPU instances are frequently scarce on short horizons, and ODCRs that lack long‑term contracts are billed at on‑demand rates, offering no inherent cost advantage. Those characteristics make ODCRs ill‑suited for transient events such as demos, workshops or short validation runs.
For practitioners the implications are clear and practical: use on‑demand for flexible, ad hoc experiments when timing is loose; use Spot for interruptible, checkpointable distributed training or retriable batch inference to maximize cost savings; and use EC2 Capacity Blocks for ML when scheduled, short‑term capacity guarantees and a predictable discount are required. The guidance retains setup limits and sharing mechanics so architects can size reservations and coordinate capacity across Organizations ahead of critical activities.
Sources
Replies (0)
No replies in this topic yet.