The article explains how AWS Lambda enables the creation of scalable and cost-effective reward functions for customizing the Amazon Nova model, facilitating the use of feedback-supported learning methods.
Creating effective reward functions is critically important for customizing Amazon Nova models, and AWS Lambda offers a scalable platform for this. The serverless architecture allows developers to focus on quality criteria while Lambda manages the computational infrastructure.
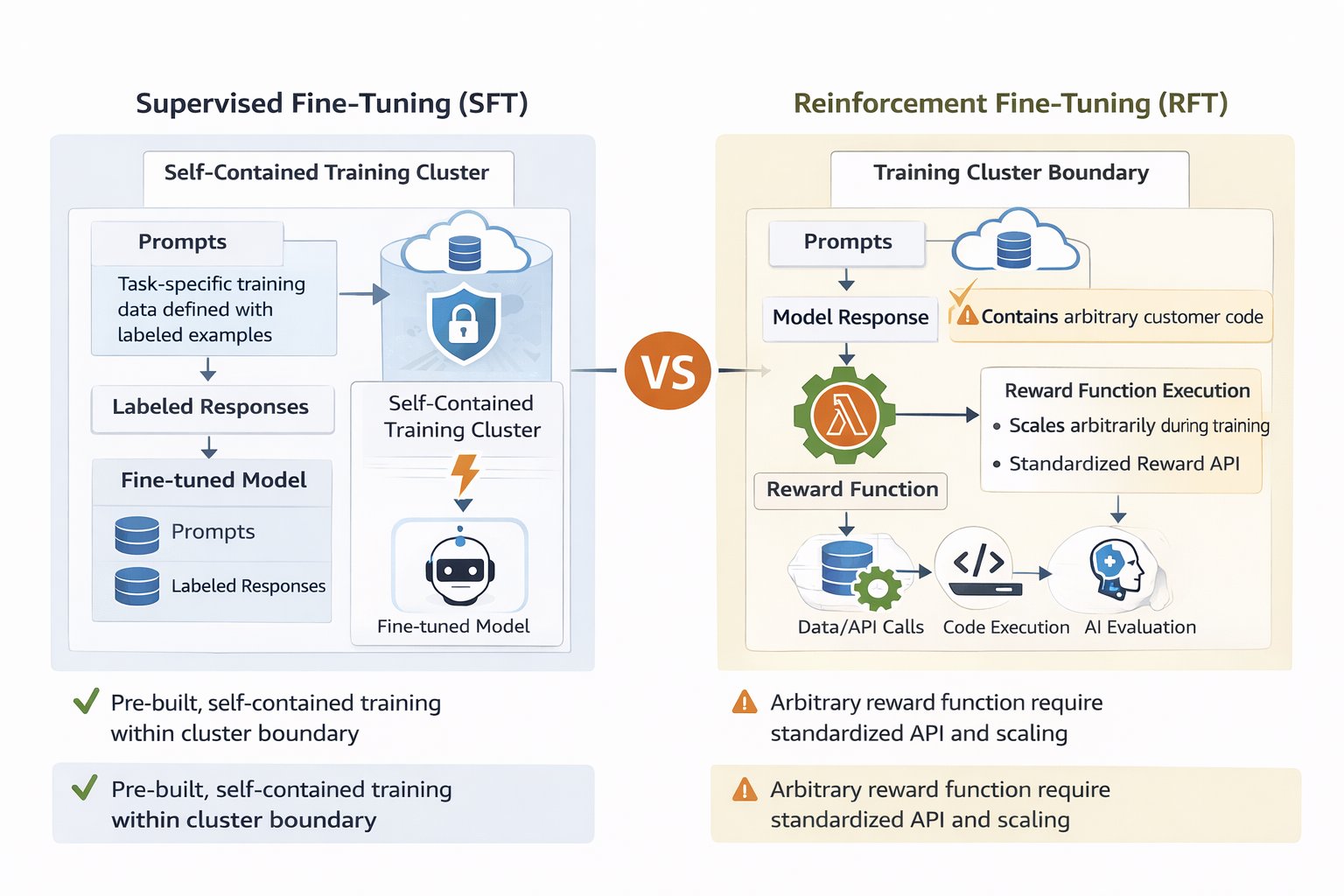
The essence of RFT lies in the reward function that evaluates and directs the model towards higher quality responses. The choice between reinforcement learning with verified rewards (RLVR) for objective tasks and AI feedback (RLAIF) for subjective assessment is considered. Strategies for designing multidimensional reward systems for different scenarios are proposed.
There are many approaches to model customization in the market, and the choice between SFT and RFT depends on the tasks. SFT is applicable when there are clear input and output examples, while RFT is better suited for balancing quality criteria such as accuracy and emotionality in responses to user queries. The RFT method requires fewer labeled examples, providing more opportunities for developers.
Using AWS Lambda to evaluate rewards creates a closed feedback loop, directing the model training process. This allows for the evaluation of model responses across various criteria without complex infrastructure management. Customizing the Nova model becomes accessible to developers without deep expertise in machine learning.
Thanks to the AWS Lambda-based architecture, customizing the Nova model also becomes cost-effective. Lambda automatically scales, providing an increase in processing from 10 to 400+ evaluations per second, eliminating the need for pre-planning infrastructure. This allows teams to focus on building and testing models, reducing costs.
Sources
Replies (0)
No replies in this topic yet.