Google announced Multi‑Token Prediction (MTP) drafters for the Gemma 4 model family, a new drafter architecture that applies speculative decoding to separate token proposal from verification. Rather than producing a single token each step, the system runs a lightweight drafter to propose short multi‑token sequences and then uses the full Gemma target model to check those sequences in parallel. The approach is designed to reduce the number of sequential forward passes required during generation.
In operation, the drafter quickly emits a draft of several tokens and the target model performs a single forward pass to verify that draft. If the target agrees with the proposed sequence it accepts the entire draft and produces one additional token, so the final output matches standard autoregressive decoding while requiring far fewer wall‑clock steps. Google cites the Gemma 4 31B model as a representative target for the MTP workflow.
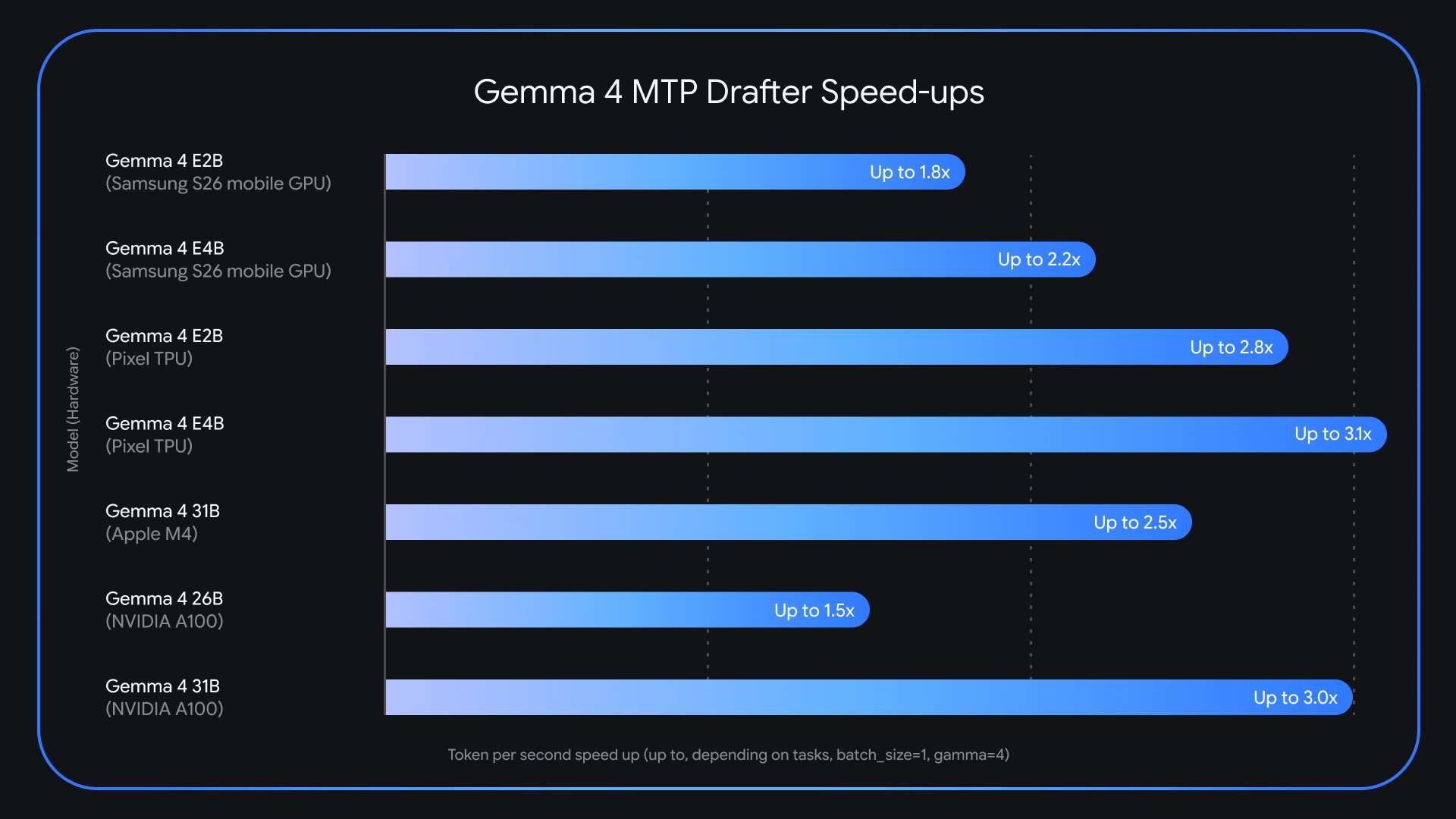
The release directly targets the long‑standing memory‑bandwidth bottleneck in large‑model inference, where autoregressive generation repeatedly fetches billions of parameters from VRAM into compute units for every token and leaves expensive compute underutilized while data moves. Gemma 4 had recently passed a 60 million downloads milestone, and Google positions MTP as an answer to that practical deployment pain point. The company reports the speculative pipeline delivers up to a 3× speedup without any loss in output quality or reasoning accuracy because the heavyweight target model still performs final verification.
MTP includes several implementation optimizations aimed at efficiency. Drafter models can reuse the target model’s activations and share the KV (key‑value) cache to avoid recomputing attention context; an embedder‑to‑layer clustering technique accelerates the final logit calculation on edge‑focused E2B and E4B Gemma 4 variants. Those edge optimizations are intended to improve end‑to‑end generation latency and throughput on hardware‑constrained devices while keeping the target model as the single source of truth for outputs.
Google also calls out hardware‑specific behavior for larger or mixture‑of‑experts variants: the Gemma 4 26B MoE model can introduce routing challenges on Apple Silicon at batch size 1, with measured performance improving when batches are raised into the 4–8 range. Overall, MTP is presented as an architecture that builders can integrate into existing transformer inference pipelines to mitigate memory‑bandwidth limits, lower latency, and improve GPU utilization for latency‑sensitive applications without changing the target model’s token‑by‑token equivalence.
Sources
Replies (0)
No replies in this topic yet.