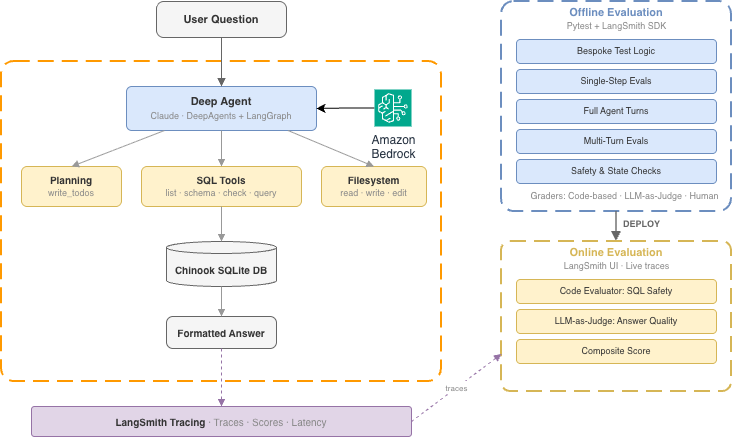
The platform team, with co-author Karan Singh, has published a technical guide that lays out a practical framework for evaluating deep agents by pairing LangSmith tooling with Amazon Bedrock hosted models. The guide targets builders wrestling with non-deterministic, multi — step agent behavior and presents concrete evaluation patterns plus an end-to-end walkthrough using a text-to-SQL agent; this matters because agentic systems require different testing and monitoring approaches than single LLM calls.
The post presents five evaluation patterns for agentic systems and shows how to build offline test suites using pytest integrated with LangSmith tracing. It also describes configuring online monitoring for production, and the hands — on walkthrough uses a text-to-SQL deep agent deployed on Amazon Bedrock to demonstrate running tasks, recording transcripts, grading runs, and aggregating results. Together these elements provide a reproducible pipeline for running, capturing and assessing agent behavior across development and production stages.
For model selection and runtime the guide highlights Amazon Nova 2 Lite on Bedrock as well-suited to agentic workloads: it is presented as a fast, cost-effective reasoning model with configurable budget levels (low, medium, high), support for text, image, video and document inputs, and a 1 million — token context window. The guide notes Nova 2 Lite performs robustly on instruction following, function calling and code generation, making it a candidate when agents need extended context and complex tool use.
The guide explains why evaluating agents is more difficult than testing single LLM responses: trials can be non-deterministic, multi — step flows can propagate and compound errors, and models may produce creative but unexpected solutions. To address that, it recommends running multiple trials per task and using probabilistic metrics — pass@k to measure the chance of at least one success in k attempts when any success suffices, and pass^k to measure the probability that all k trials succeed when consistency is required.
Key terminology and the evaluation structure are preserved to aid reproducibility: Task (a single test with inputs and success criteria), Trial (one attempt), Grader (the scoring logic), Transcript (the full trace of tool calls, reasoning steps and intermediate outputs), Outcome (the final environment state), Evaluation harness (the infrastructure that runs, records and grades) and Evaluation suite (a collection of tasks). record full transcripts to debug cascading errors, design graders to capture multiple correctness dimensions, run multiple trials to estimate reliability, and combine offline pytest — based suites with LangSmith tracing and production monitoring to detect regressions early and iterate on agent design.
Sources
Replies (0)
No replies in this topic yet.