Hexo Labs released SIA (Self‑Improving AI) under the MIT license: An open‑source framework that runs a loop where a Feedback Agent chooses to rewrite an agent’s scaffold or trigger weight updates to the underlying model.
Hexo Labs this week published SIA (Self‑Improving AI) as an open‑source framework under the MIT license. SIA implements a closed loop that alternates between editing an agent’s harness (the scaffold around a model) and updating model weights, with the stated aim of continuing improvement after human tuning stops. The team released a technical report, code repository, and benchmark results alongside the announcement.
SIA decomposes a task agent into two components: the harness — which includes the system prompt, tool dispatch, retry policy and extraction code-and the model weights. Three LLM components drive the loop: a Meta Agent that produces an initial scaffold, a Task‑Specific Agent that executes tasks and logs trajectories, and a Feedback Agent that reads trajectories and decides whether to rewrite the scaffold or apply a weight update. Weight updates are applied as LoRA on gpt-oss-120b at rank 32. The Meta and Feedback agents run on Claude Sonnet 4.6, and training runs used H100 GPUs via Modal.
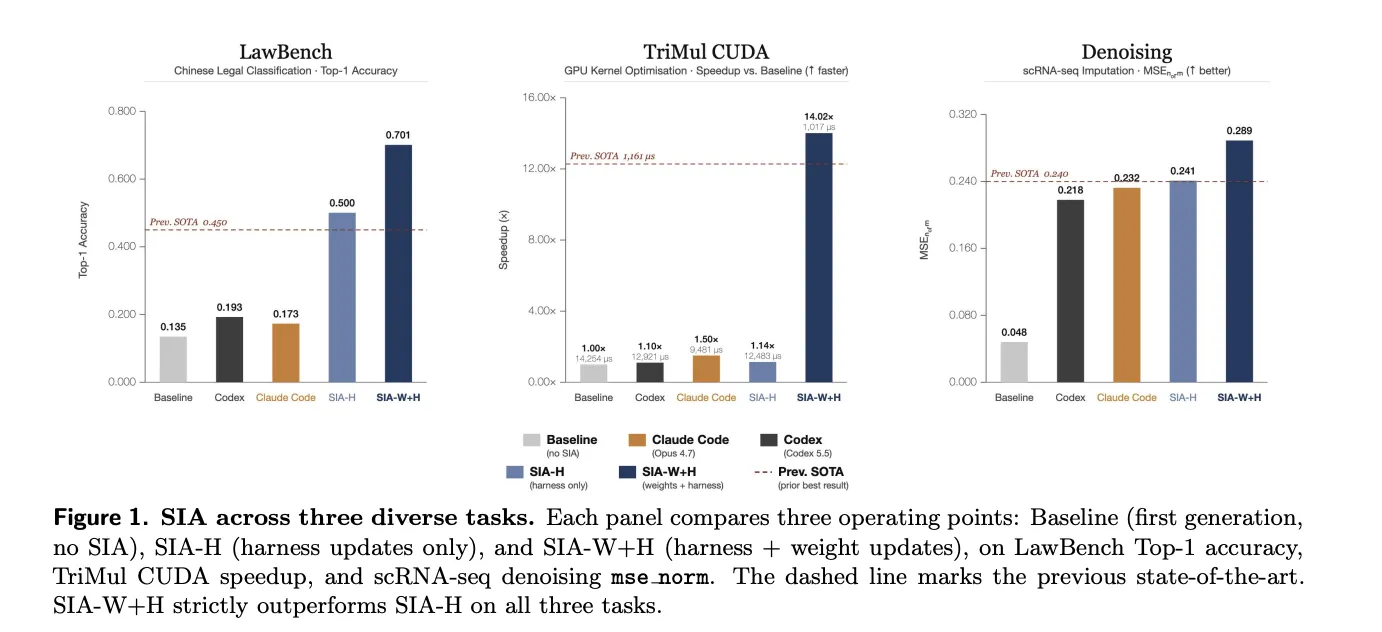
The repository supports two operating modes: SIA‑H, which updates only the harness, and SIA‑W+H, which updates both harness and weights within the same loop. The paper reports quantitative results on three diverse benchmarks. On LawBench—a 191‑class Chinese criminal charge classification task-the base model began at 13.5% top‑1 accuracy, prior state of the art was 45.0%, SIA‑H reached 50.0%, and SIA‑W+H reached 70.1%.
On AlphaEvolve TriMul, which optimizes a CUDA kernel for an Evoformer operation, reported rewards moved from an initial 0.105 and a prior SOTA of 1.292 to 0.120 for SIA‑H and 1.475 for SIA‑W+H. Under weight updates the runtime for the target kernel fell from 12,483 µs to 1,017 µs. For the MAGIC single‑cell denoising benchmark the paper gives mse_norm values: initial 0.048, prior SOTA 0.240, SIA‑H 0.241 and SIA‑W+H 0.289.
The Feedback Agent does not rely on a single fixed reinforcement recipe; it selects training algorithms conditioned on observed rewards and failure modes. For LawBench the team used PPO with GAE because the reward is a clean outcome scalar; TriMul training used entropic advantage weighting to up‑weight rare, compilable high‑reward rollouts; and denoising used GRPO without a value network. The report also evaluated alternatives — including REINFORCE with KL‑to‑base, DPO, and best‑of‑N behavioral cloning — mapped to different reward shapes and risk profiles.
Sources
Replies (0)
No replies in this topic yet.