Marwan Sarieddine published a technical blog post on May 14, 2026 that diagnoses why production multimodal AI pipelines frequently leave GPUs idle and proposes an architectural remedy. He shows that the bottleneck is not the models themselves but upstream, CPU‑heavy preprocessing, and he recommends a disaggregated streaming model — demonstrated in Ray Data-to keep long‑lived GPU workers continuously fed without materializing large intermediates. This matters to teams running training or inference at scale because sustained GPU utilization directly affects throughput and cost.
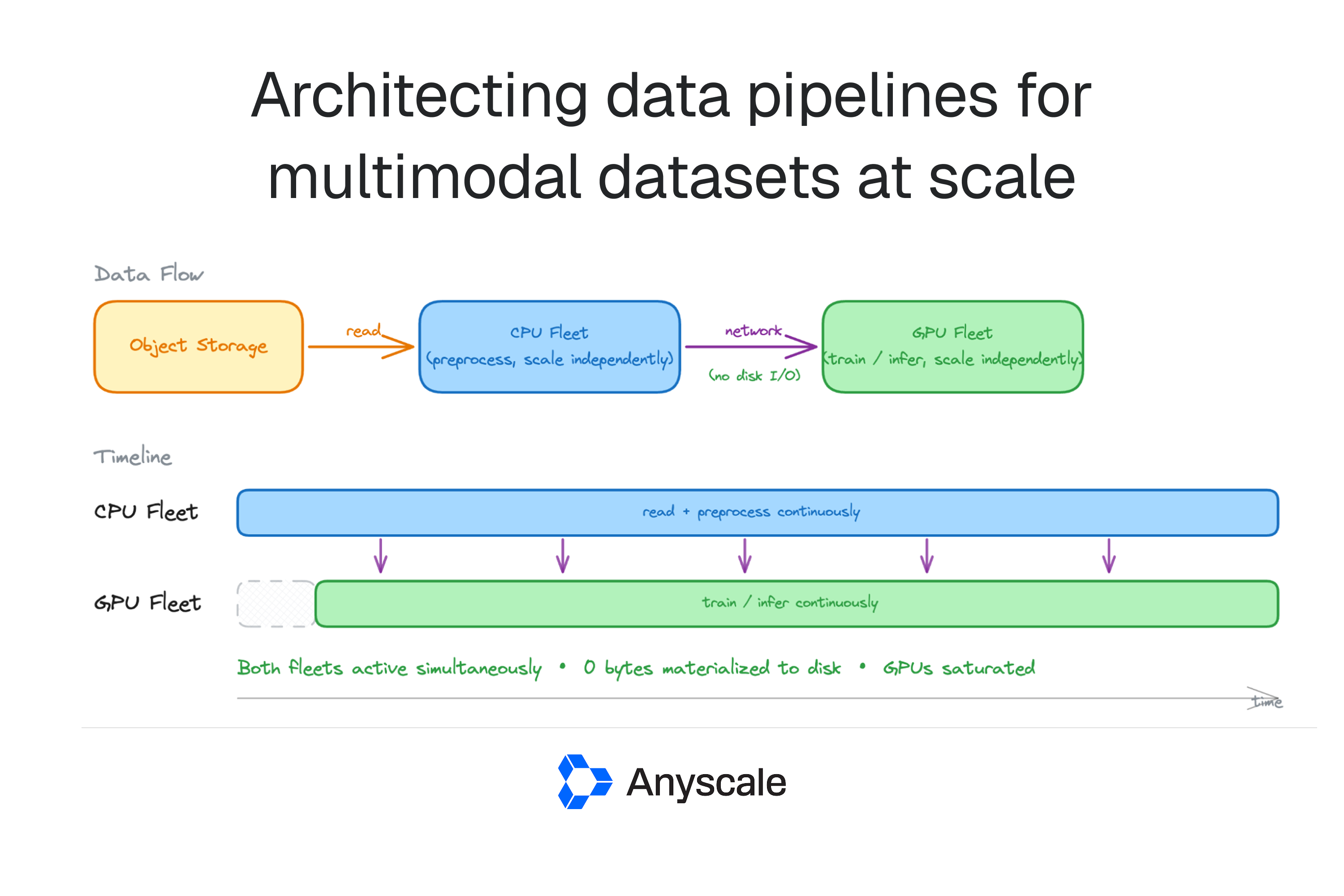
Sarieddine quantifies the imbalance: CPU‑bound preprocessing can consume as much as 65% of total epoch time on multimodal workloads. Video decoding, lidar/point‑cloud voxelization, audio transforms and OCR must complete before a GPU can consume a batch, so expensive CPU tasks can dominate end‑to‑end epoch timing even when model computation itself is fast. GPUs in these setups typically run as long‑lived, stateful workers that keep model weights resident in memory across batches; that design requires a continuous stream of ready inputs to avoid idle accelerators. When preprocessing cannot supply that stream, GPU instances stall and overall pipeline throughput collapses despite ample accelerator capacity.
Sarieddine examines two common, but flawed, architectures. In staged batch execution, expanded intermediates are materialized to object storage, which can multiply dataset size by 2×–10×. Using his example of a 500 TB raw dataset with 2× expansion, a 32‑node CPU fleet and an 8‑node GPU fleet, the I/O timeline was: read 500 TB ≈ 1.5 hours, write 1 PB ≈ 3 hours, read 1 PB ≈ 12 hours — about 16.5 hours of I/O that leave CPUs or GPUs idle and inflate epoch latency.
Single‑node execution is also suboptimal because GPU instance families provide limited vCPUs per GPU. Sarieddine lists concrete examples: p4d.24xlarge offers 96 vCPUs and 8 A100 GPUs (12 vCPUs/GPU); p5.48xlarge offers 192 vCPUs and 8 H100 GPUs (24 vCPUs/GPU). For heavy preprocessing workloads—H.264 decoding, lidar projection, OCR-those per‑GPU CPU budgets are often insufficient to sustain the throughput GPUs need.
The proposed remedy is disaggregated streaming: run a separate preprocessing fleet that streams preprocessed inputs directly to the long‑lived GPU workers so intermediates need not be fully materialized to storage. Ray Data is presented as an implementation of this pattern; intermediates can still be retained for debugging and replayability, but streaming reduces storage I/O, shortens cold starts, and avoids large temporary storage footprints for epoch‑specific augmentations.
Sources
Replies (0)
No replies in this topic yet.