JetBrains published Mellum2 weights under the Apache 2.0 license and released six checkpoints covering pretraining, context expansion, instruction — tuning and RL tuning, including distinct Instruct and Thinking variants.
JetBrains has published Mellum2 weights under an Apache 2.0 license and made six checkpoints available, positioning the model as a fast, specialized component for multi‑model pipelines and agentic flows rather than as a frontier replacement. The release matters because Mellum2 combines a Mixture‑of‑Experts (MoE) design with a very long context — claimed at roughly 131,072 tokens — enabling high‑capacity, low‑latency components for tasks like large codebase reasoning and multi‑step debugging. Teams integrating the model should treat JetBrains’ benchmarks as self‑reported and validate performance in their own scenarios.
Architecturally, Mellum2 is a Mixture‑of‑Experts model totaling 12 billion parameters, with about 2.5 billion parameters active per token through 64 experts and eight experts activated per token. The network has 28 layers, a hidden size of 2,304, and uses Grouped‑Query Attention with 32 query heads and 4 KV heads. It applies a Sliding Window Attention window of 1,024 to three out of four layers and full attention on the remaining layer. The model uses a Multi‑Token Prediction (MTP) head, bfloat16 precision, and a vocabulary of 98,304 tokens.
Mellum2 understands natural language and code but does not handle images or video. Pretraining used roughly 10.6 trillion tokens over a three‑phase curriculum that shifted data from broad web content toward curated code and mathematics corpora. Training employed the Muon optimizer with hybrid FP8 precision and a Warmup — Hold–Decay learning rate schedule with linear decay to zero. JetBrains extended the base model’s context to about 128K tokens using a layer‑selective YaRN method before subsequent tuning.
The company released six checkpoints that mirror stages of the pipeline: Base‑Pretrain (before context expansion), Base (after expansion), Instruct‑SFT, Thinking‑SFT, Instruct RL‑tuned and Thinking RL‑tuned. The Instruct variant is tuned for concise, low‑latency answers, tool use and instruction following. The Thinking variant emits an explicit chain — of‑thought style trace of reasoning prior to the final response and is targeted at complex debugging, multi‑step planning and agent workflows.
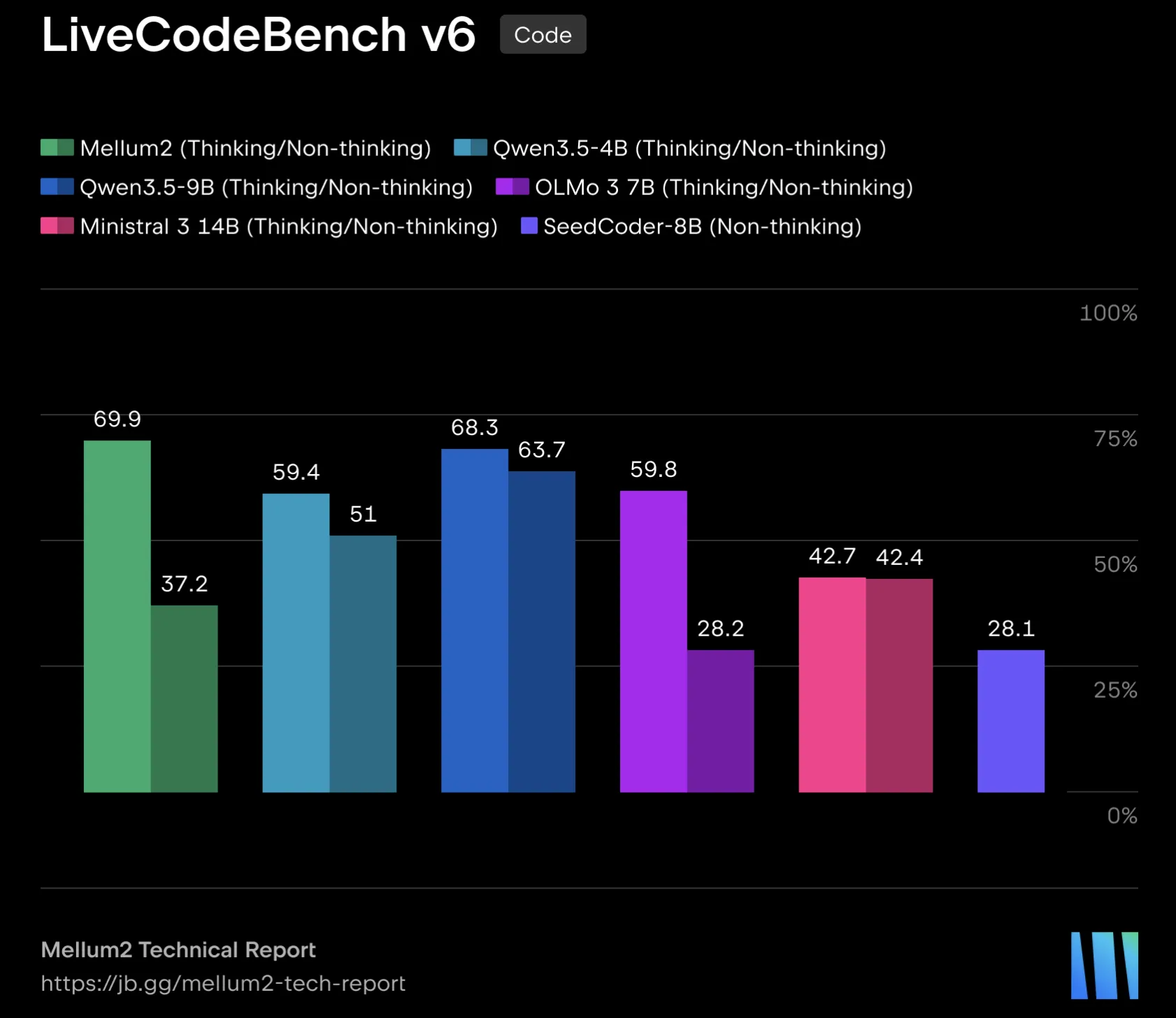
JetBrains published self‑declared benchmarks comparing Mellum2 to open models in the 4B-14B range. On LiveCodeBench v6, Mellum2 Instruct scored 37.2 versus Qwen3.5 (4B) at 51.0 and Mistral 3 (14B) at 63.7; on EvalPlus Mellum2 scored 78.4. Tooling benchmarks show BFCL v3 at 66.3 and BFCL v4 at 44.2. Mathematical and reasoning scores include AIME (2025+2026) 41.7 and GSM‑Plus 80.5; knowledge/dialogue MMLU‑Redux is 78.1 while some competitors report 87+. JetBrains notes these are internal results and recommends external verification.
For developers, Mellum2 offers a deployment tradeoff: because MoE routing activates only a fraction of parameters per token, per‑token compute is close to that of a dense 2.5B model, easing low‑latency component deployment while retaining increased parameter capacity for specialization. The extended 128K-131K context is intended for large codebases and long debugging sessions but requires runtime support for MoE routing and compatible hardware and software stacks.
Sources
Replies (0)
No replies in this topic yet.