LightSeek Foundation released TokenSpeed, an MIT-licensed open-source LLM inference engine now in preview that targets the latency and throughput demands of agentic coding systems by optimizing per — GPU tokens per minute and per-user tokens per second.
LightSeek Foundation has published TokenSpeed, an MIT-licensed, open-source LLM inference engine now available in preview. The project targets the “agentic” class of systems — coding agents and multi — turn developer tools — where inference patterns differ from typical chat use and place unusual demands on serving stacks. By focusing on the specific performance profile of these systems, TokenSpeed aims to make agentic tools both more scalable and more responsive for users.
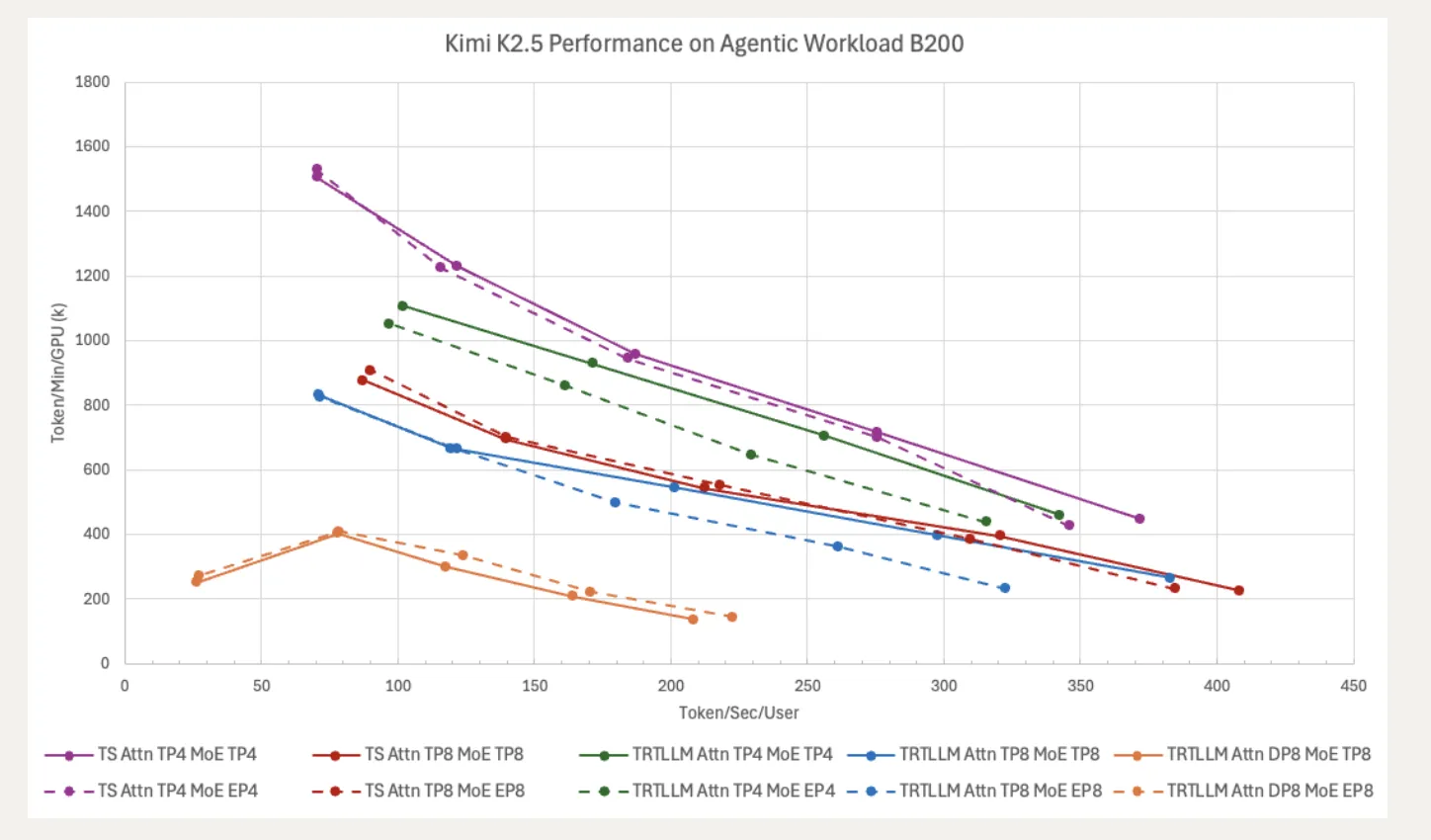
TokenSpeed is tuned to optimize two linked metrics that matter for agentic workloads: per — GPU TPM (tokens per minute), to maximize how many users a single GPU can serve, and per-user TPS (tokens per second), to keep individual interactions responsive. The team sets a per-user TPS floor typically at 70 TPS and often aims for 200 TPS or higher. Those targets reflect agentic contexts that can routinely exceed 50,000 tokens and span dozens of turns, creating sustained and concurrent inference demands that differ from short — chat scenarios.
The engine is organized around five interlocking subsystems intended to handle long contexts and complex request lifecycles: a compiler — backed modeling mechanism for parallelism, a high-performance scheduler, a safe key-value (KV) resource reuse restriction, a pluggable layered kernel system for heterogeneous accelerators, and SMG integration as a low-overhead CPU-side entrypoint. Together these pillars address parallelism, scheduling, resource safety, hardware heterogeneity, and efficient CPU-GPU handoff.
TokenSpeed’s modeling layer adopts a local SPMD (Single Program, Multiple Data) approach and lets developers add I/O placement annotations at module boundaries. A lightweight static compiler emits the necessary collective operations during model construction so developers avoid implementing inter — process communication manually. Shifting communication correctness into compilation is intended to catch coordination errors earlier and simplify model code for long, multi — turn contexts.
The scheduler separates control and execution to balance safety and developer iteration speed. The control plane is a C++ finite — state machine that uses the type system to enforce safe resource management and KV-cache state transitions at compile time, encoding request lifecycle, KV ownership, and overlap timing to catch KV-cache errors early. The execution plane is implemented in Python to preserve fast iteration for developers while the control plane provides compile — time guarantees.
TokenSpeed treats GPU kernels as first — class plugins with a portable API and registry to support heterogeneous hardware rather than locking to a single vendor. The team developed a high-performance MLA kernel tuned for NVIDIA Blackwell: the decode kernel groups q_seqlen and num_heads to better utilize Tensor Cores, and the binary prefill kernel includes a fine-tuned softmax. TokenSpeed’s MLA implementation has already been adopted by vLLM. SMG, a PyTorch — native component, provides a low-overhead CPU-side request entrypoint to reduce handoff costs during serving.
Sources
Replies (0)
No replies in this topic yet.