Liquid AI has released LFM2.5 — 8B-A1B, a Mixture — of-Experts (MoE) model designed for on-device reasoning and tool use that holds 8.3 billion total parameters while activating roughly 1.5 billion per forward pass. That reduced active footprint, Liquid says, keeps per-token compute low enough to enable sustained chain — of-thought generation and agentic workflows on CPUs, phones and edge GPUs where dense large models would be impractical.
Architecturally, LFM2.5 — 8B-A1B uses 24 layers made up of 18 double — gated LIV convolution blocks and six GQA layers, combining MoE, GQA and gated short convolution components. It is configured as a reasoning — only model that emits an explicit chain — of-thought before producing a final answer. Liquid recommends inference settings of temperature 0.2, top_k 80 and a repetition_penalty of 1.05.
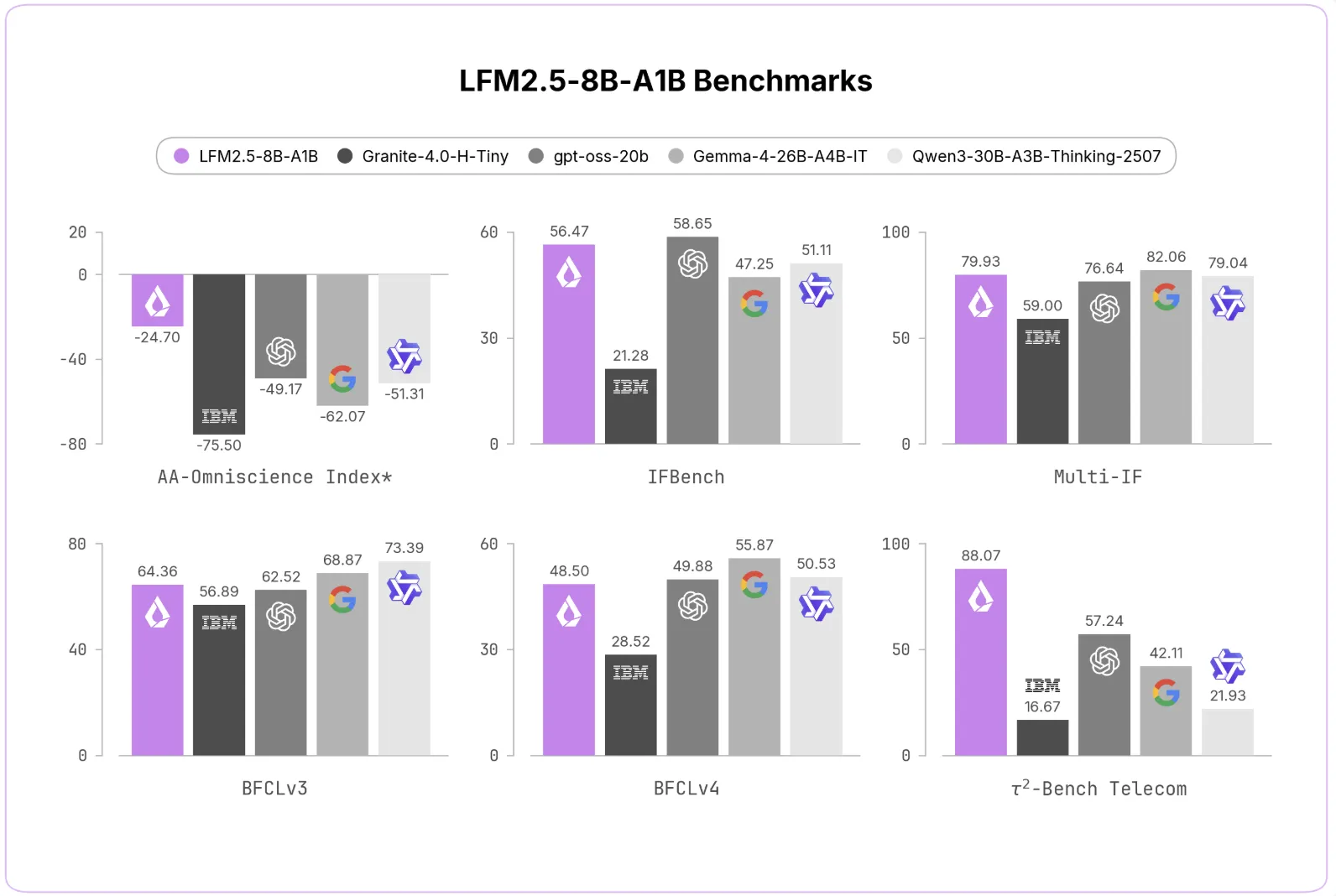
Against its predecessor LFM2-8B-A1B and larger dense and MoE alternatives, Liquid reports substantial benchmark gains: AA — Omniscience Non — Hallucination Rate rose from 7.46 to 63.47; IFEval improved from 79.44 to 91.84; MATH500 climbed from 74.80 to 88.76; and Tau² Telecom jumped from 13.60 to 88.07. The team also says LFM2.5 matches Gemma — 4-26B-A4B-IT on IFEval while using far fewer active parameters per token.
For builders, the combination of a large sparse model with a small active parameter footprint and long context is intended to lower latency and cost for on-device agents and tool-calling workflows. Liquid highlights that the lower active count makes every reasoning token cheaper, which supports prolonged chain — of-thought inference and agentic behavior on consumer hardware where dense models would be too costly or slow.
Training and adaptation work included scaling pretraining from 12 trillion to 38 trillion tokens and expanding the tokenizer in place rather than rebuilding it. Context extension was performed in two phases: a 2 trillion — token midtraining stage that reached a 32K context and emphasized reasoning, math and tool use, followed by RoPE-base (θ) adjustments plus a 400 billion — token stage to reach an extended 128K context (reported as 131,072 tokens). Liquid also applied two reinforcement — learning stages — a preference — optimization pass to reduce long-loop failures and an avg@k-shaped reward to cut hallucinations and encourage abstention on unreliable queries.
LFM2.5 — 8B-A1B ships with day-one support across popular runtimes and tooling, including llama.cpp, MLX, vLLM, SGLang, ONNX and Liquid’s LEAP edge platform. Cited performance figures include about 253 tokens/s on an Apple M5 Max CPU, roughly 146 tokens/s on a Ryzen AI Max+ 395, around 30 tokens/s on a phone, and up to 18.5K tokens/s on a single NVIDIA H100 SXM5 (exceeding 1.6 billion tokens per day at high concurrency), with memory remaining under 6 GB in the cited CPU cases.
Sources
Replies (0)
No replies in this topic yet.