The inherent challenge with large language models (LLMs) lies in the fact that their raw outputs frequently contain inaccuracies, policy misalignments, or unhelpful phrasing. These issues critically undermine user trust and limit the practical utility of these powerful systems in real-world applications. To address these deficiencies, Reinforcement Fine — Tuning (RFT) has emerged as the preferred methodology for efficiently aligning LLMs.
The RLAIF paradigm distinguishes itself by deploying a dedicated language model to function as an independent 'judge.' This judge LLM meticulously evaluates candidate responses generated by the primary model, subsequently providing feedback to guide the alignment process. This contrasts sharply with generic RFT methods that might rely on simpler, hand-crafted rules, as seen in RLVR, or blunt numeric scoring mechanisms like substring matching. The LLM-as-a-judge approach significantly enhances alignment flexibility and power, proving particularly effective in scenarios where reward signals are ambiguous or difficult to articulate and quantify manually, thereby offering a more nuanced steering mechanism for model behavior.
A key advantage of the LLM-as-a-judge methodology is its capacity for multi — dimensional reasoning. Unlike static reward functions, an LLM judge can assess outputs across various critical dimensions, including correctness, tone, safety, and relevance. This capability allows for context — aware feedback that adeptly captures subtle nuances and domain — specific characteristics without the need for extensive task-specific retraining. Furthermore, LLM judges provide inherent explainability through rationales, such as a note stating, 'Response A cites peer-reviewed studies.' These diagnostic insights accelerate the iteration cycle, directly pinpoint failure modes, and help in reducing hidden misalignments, features that are generally absent in less sophisticated, static reward functions.
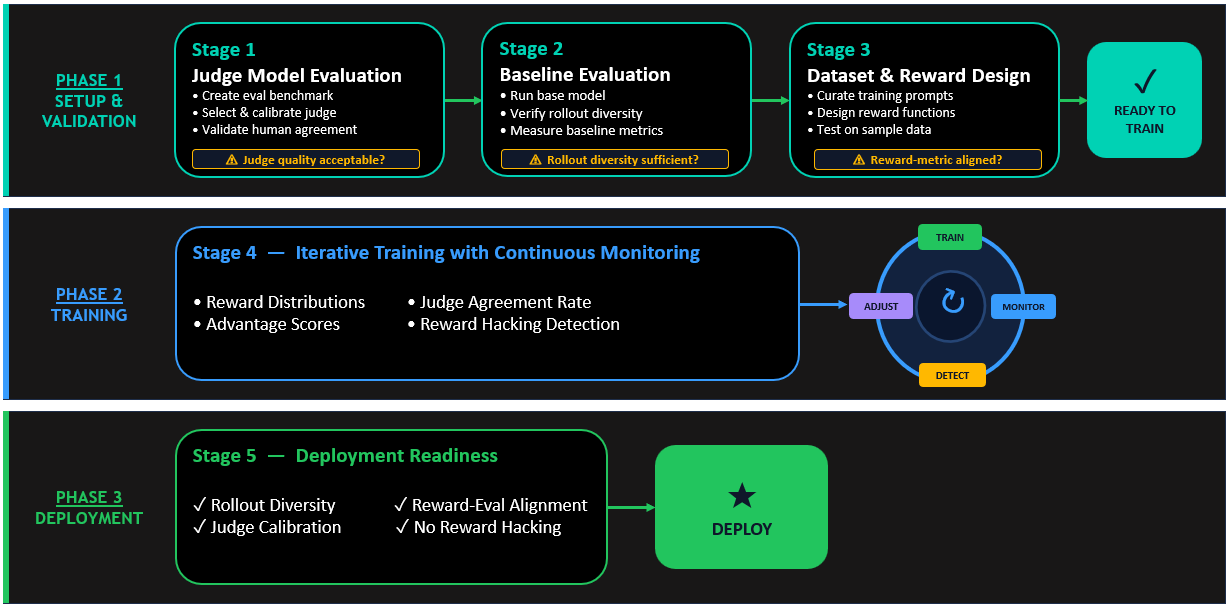
Implementing an LLM-as-a-judge system begins with the crucial decision of selecting the appropriate judge architecture, which largely dictates the evaluation methodology. Two primary modes are available: Rubric — based judging and Preference — based judging. Rubric — based judging assigns a numeric score to a single response based on predefined criteria, excelling when clear, quantifiable evaluation dimensions, such as accuracy, completeness, or safety compliance, are paramount. This method provides an absolute quality measurement. Conversely, Preference — based judging involves a side-by-side comparison of two candidate responses, with the judge selecting the superior one.
Following the architectural decision, the next vital steps involve defining explicit evaluation criteria and carefully selecting and configuring the judge model itself. For Preference — based judges, this translates into crafting clear prompts that detail what makes one response superior to another, using concrete examples to articulate quality preferences. For Rubric — based judges, the recommendation is to employ Boolean (pass/fail) scoring, which enhances reliability and minimizes judge variability compared to more granular 1 — 10 scales, requiring specific, observable characteristics for pass/fail criteria. The choice of judge model requires selecting an LLM with sufficient reasoning capabilities for the target domain.
Ultimately, the sophisticated application of LLM-as-a-judge methods delivers tangible improvements to the development and deployment of AI. By providing rich, context — aware scores to the reinforcement learning algorithm, this approach effectively 'nudges' the LLM toward generating more aligned and desirable solutions. This paradigm shift offers a robust mechanism for developers and enterprises to overcome the initial challenges of LLM output quality, accelerating the identification and correction of model deficiencies. The result is the cultivation of more dependable, trustworthy, and ultimately more useful AI systems that are better aligned with user intent and real-world requirements.
Sources
Replies (0)
No replies in this topic yet.