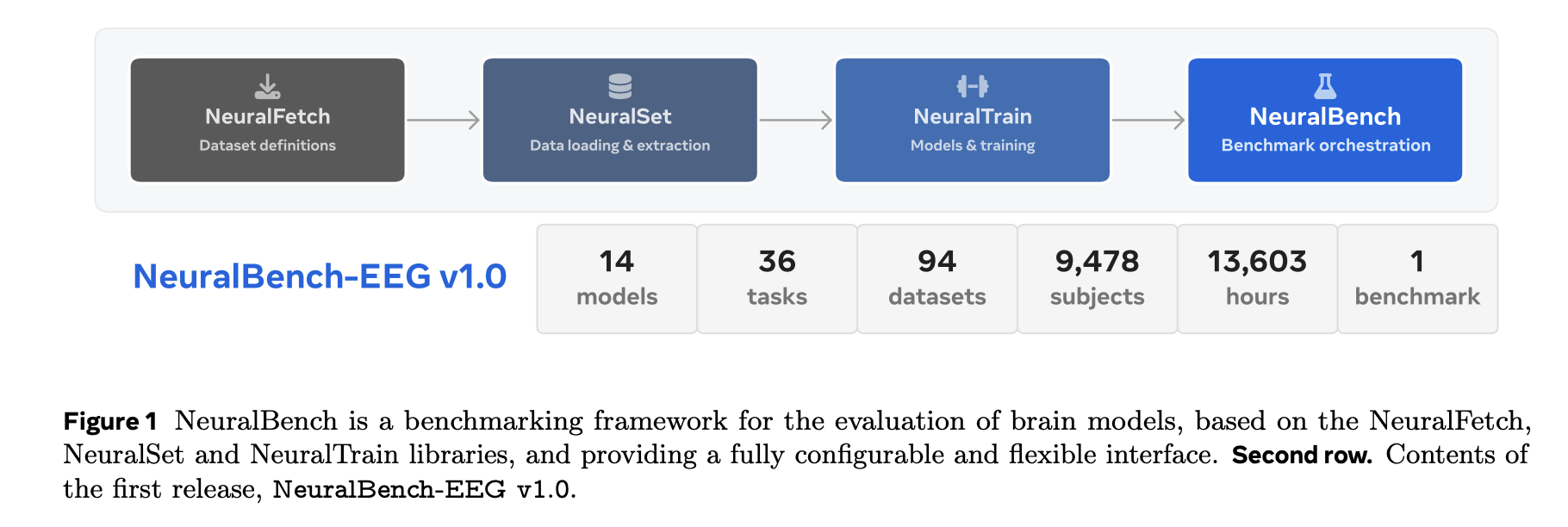
Meta AI has published NeuralBench and its first dataset release, NeuralBench — EEG v1.0, to provide a unified, open-source benchmark and pipeline for NeuroAI. The release aims to make cross — task comparisons more straightforward by offering a single standardized interface for data loading, preprocessing and model evaluation. NeuralBench — EEG v1.0 consolidates 36 downstream tasks drawn from 94 datasets, covering 9,478 subjects and 13,603 hours of electroencephalography (EEG) data. The package evaluates 14 deep learning architectures under the shared interface so that results from different models and tasks can be directly compared without bespoke data handling or evaluation code.
NeuralBench is implemented as three modular Python packages. NeuralFetch acquires datasets from public repositories such as OpenNeuro, DANDI and NEMAR. NeuralSet produces PyTorch — ready dataloaders, wraps established neuroscience tools (MNE — Python, nilearn) and uses HuggingFace to extract stimulus embeddings when required. NeuralTrain supplies training code built on PyTorch Lightning, Pydantic and the exca execution/caching library. Users can download data, prepare the cache, and execute tasks defined by lightweight YAML configs that specify splits, preprocessing, targets, hyperparameters and metrics.
The release addresses a fragmented evaluation landscape in NeuroAI. Prior efforts, such as MOABB, cover many BCI datasets but constrain the range of downstream tasks; other benchmarks (EEG — Bench, EEG — FM-Bench, AdaBrain — Bench) have their own limitations. Modalities like MEG and fMRI still lack a similarly systematic, cross — task benchmark, while the rapid rise of self-supervised pretraining and brain foundation models increases the need for consistent cross — task assessment.
NeuralBench v1.0 evaluates three model classes and supplies a shared fine-tuning recipe so results are comparable. It contrasts task-specific architectures (~1.5K–4.2M parameters) against EEG foundation models (~3.2M-157.1M parameters) and handcrafted feature baselines that use symmetric positive definite (SPD) matrix pipelines with logistic or Ridge regression. Foundation models are fine-tuned end-to-end using AdamW with a learning rate of 1e-4 and weight decay set to 0; BENDR is the exception, using a learning rate of 1e-5 plus gradient clipping at 0.5.
The EEG benchmark spans eight task categories — cognitive decoding (image, sentence, speech, typing, video and word decoding), brain — computer interfacing, evoked responses, clinical tasks, internal state estimation, sleep scoring, phenotyping and miscellaneous tasks. Architectures evaluated include ShallowFBCSPNet, Deep4Net, EEGNet, BDTCN, AT, EEGConformer, SimpleConvTimeAgg and CTNet, alongside foundation models such as BENDR, LaBraM, BIOT, CBraMod, LUNA and REVE.
Sources
Replies (0)
No replies in this topic yet.