Researchers at Meta FAIR, Stanford University and the University of Washington propose three inference methods for the Byte Latent Transformer (BLT) that cut inference memory‑bandwidth costs by over 50% while generating directly from raw bytes rather than subword tokens. The improvement targets a key practical constraint in large‑model deployments: reducing the number of decoder forward passes lowers memory loads and can materially improve throughput and latency when memory bandwidth is the bottleneck.
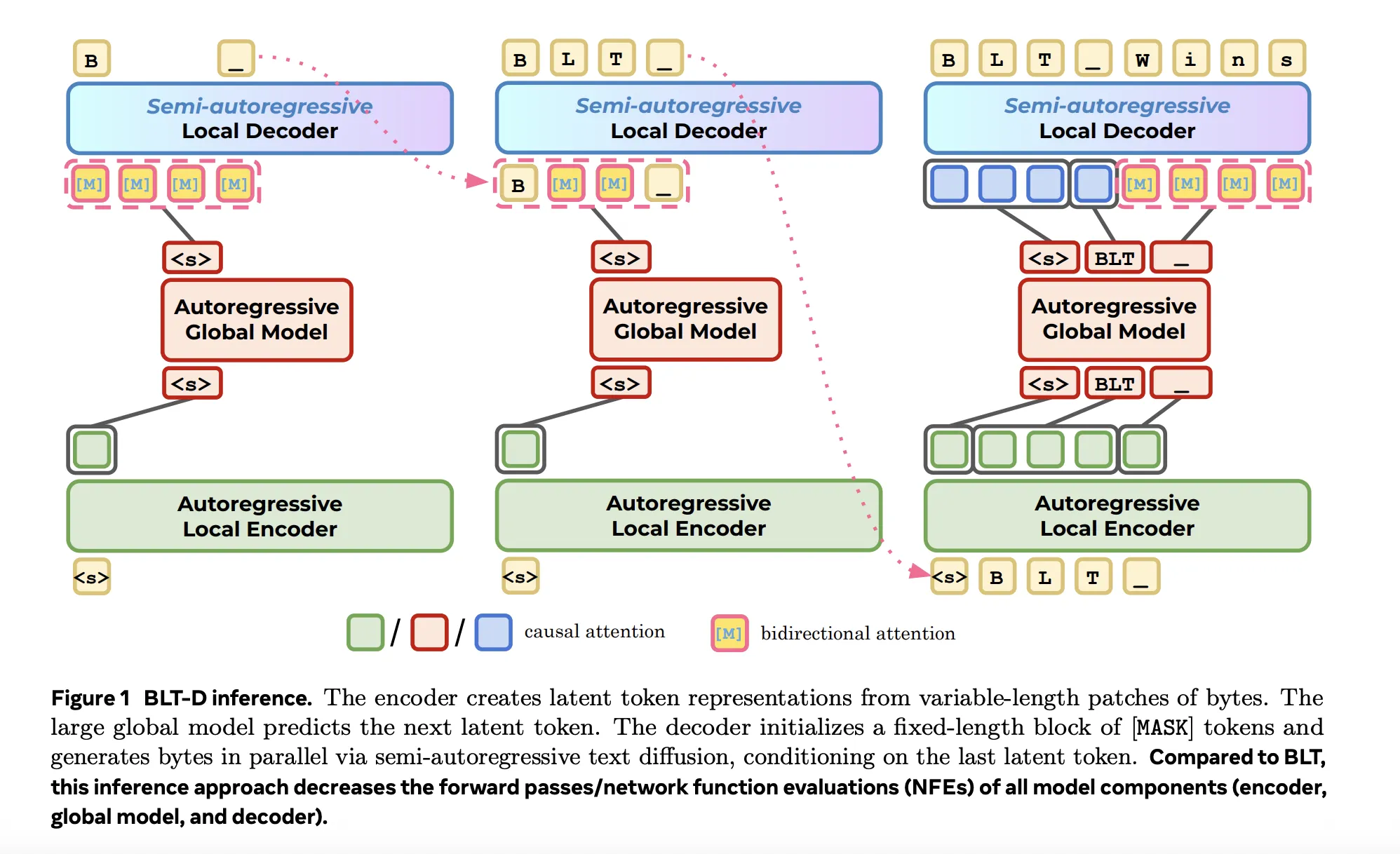
BLT is a byte‑level language model that groups raw bytes into variable‑length patches using an entropy‑based segmentation strategy. Its hierarchical design combines a local encoder, a large global Transformer, and a local decoder; the model’s average patch size is four bytes with an eight‑byte maximum. At scale BLT matched token‑level performance, but inference remained slow because the local decoder originally generated bytes autoregressively, one at a time.
The team identifies memory bandwidth as the primary inference bottleneck: each decoder forward pass increases reads of model weights and key‑value (KV) caches from memory, limiting throughput on modern serving hardware. To reduce these loads, the researchers present three methods that trade generation speed for output quality by reducing the number of decoder invocations per output span; the paper focuses in depth on the most effective of these, BLT Diffusion (BLT‑D).
BLT‑D replaces byte‑by‑byte autoregression in the local decoder with block‑wise discrete diffusion. During training is shown both the clean byte sequence and a corrupted version composed of fixed‑length blocks; a diffusion timestep t sampled uniformly from (0,1) sets the per‑byte masking probability. Experiments reported in the paper use block sizes B = 4, 8, or 16 bytes, and training optimizes a combination of the autoregressive next‑byte loss and a masked‑byte prediction loss.
At inference, BLT‑D initializes blocks as [MASK] and iteratively unmasks multiple byte positions per decoder step instead of producing a single byte. The paper evaluates two unmasking strategies: confidence‑based unmasking, which reveals positions exceeding a threshold α, and entropy‑bounded (EB) sampling, which selects the largest subset whose cumulative entropy does not exceed γ. Because the encoder and global Transformer are invoked once per block rather than once per patch, BLT‑D delivers many more bytes per forward pass.
For builders, the practical implications are direct: fewer decoder passes mean fewer memory loads for model weights and KV caches, which can improve latency and throughput in deployments where memory bandwidth constrains performance. BLT‑D also supports KV caching and exposes parameters (block size B, threshold α, entropy bound γ) so teams can tune the speed — quality tradeoff for their workloads. Full experimental details, evaluation results and implementation notes are available in the authors’ technical writeup on arXiv (2605.08044), which the paper cites for teams exploring byte‑level generation for multilingual, noisy, or structured inputs.
Sources
Replies (0)
No replies in this topic yet.