Major labs have used model — to-model distillation to transfer reasoning and instruction — following from large models into smaller ones.
Meta, Google and DeepSeek have moved LLM‑to‑LLM distillation from research experiments into production training pipelines to transfer reasoning and instruction behavior into smaller models. That shift matters because it lets teams inherit capabilities from larger systems while reducing the deployment cost and latency of running smaller models in products.
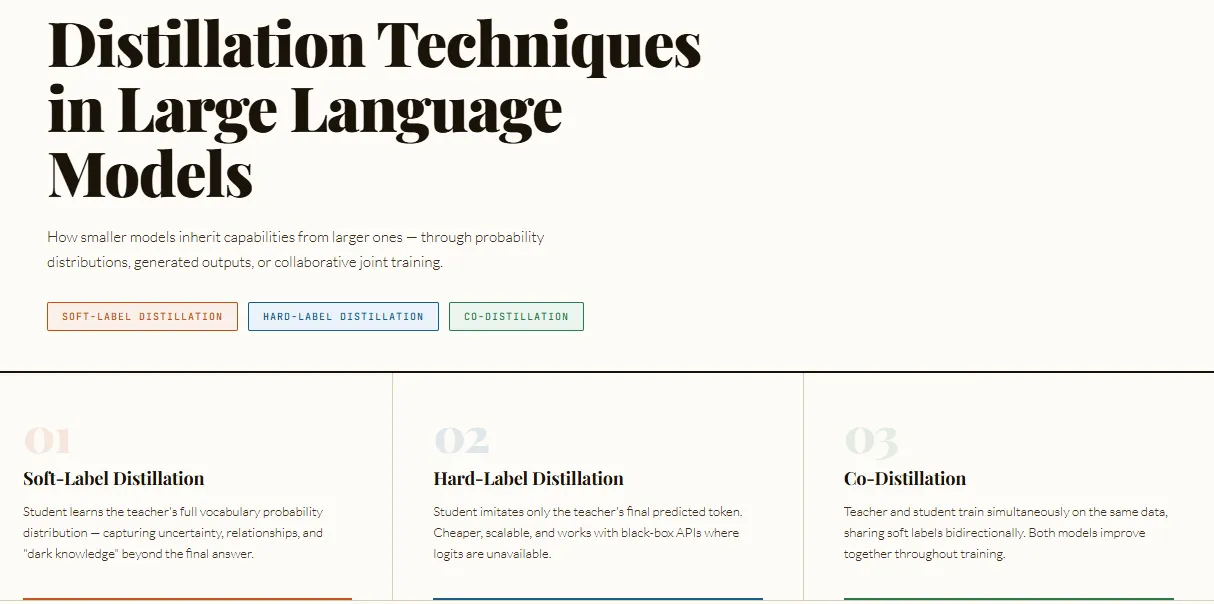
Practitioners use three primary distillation approaches. Soft‑label distillation exposes the teacher’s full probability distribution over tokens — its so‑called “dark knowledge”—so the student learns not just the final answer but the relative likelihoods of alternatives (for example: “cat” 70%, “dog” 20%, “animal” 10%). That richer training signal can transfer nuanced reasoning and behavior, but typically requires access to the teacher’s logits or weights and large storage to capture distributions across vocabularies with 100k+ tokens.
Hard‑label distillation is simpler: the teacher generates final outputs that become supervised targets for the student. It is far less storage‑heavy and practical when the teacher is a proprietary, black‑box service (for example, GPT‑4 APIs) where logits aren’t available. The reporting notes DeepSeek used hard‑label‑style methods to move capabilities into smaller Qwen and Llama 3.1‑class models.
Distillation timing also varies and affects engineering trade‑offs. It can occur during pre‑training, when teacher and student are trained together and can co‑optimize behaviors, or post‑training, when a fully trained teacher generates labels, traces or responses for a separate student to consume. Co‑distillation falls between these options: multiple models learn collaboratively by sharing predictions and behaviors during training, allowing joint improvements but requiring synchronized pipelines and more compute coordination.
For builders the choice is pragmatic: use soft‑labels when you can access teacher internals and afford the storage and compute to preserve probability distributions; prefer hard‑labels when constrained to black‑box APIs or when storage capacity is limited; and consider co‑distillation when you can coordinate multiple models to learn from one another. These patterns let teams inherit advanced behaviors from large models while reducing inference cost compared with training only on raw text.
Sources
Replies (0)
No replies in this topic yet.