Microsoft Research’s AI Frontiers lab has released Fara1.5, a trio of browser computer‑use agents (4B, 9B and 27B parameters) packaged to run inside MagneticLite, the team’s sandboxed browser interface for agent‑driven web tasks. The release is paired with FaraGen1.5, a synthetic training pipeline intended to produce ground‑truth trajectories and end‑to‑end verification, which together aim to simplify building, testing and safely deploying web agents.
Fara1.5 is built from Qwen3.5 base checkpoints and operates in an observe — think–act loop: at each step the agent ingests the prior conversation history plus the three most recent browser screenshots, emits internal 'thoughts', and then outputs a single next action. The models’ action space covers low‑level inputs (mouse and keyboard), web‑specific operations such as search, and higher‑level meta‑actions like memorizing facts or asking clarification questions to manage longer workflows.
Training used supervised fine‑tuning on roughly two million samples with a defined mix of data types: about 60% web trajectories, 12.8% synthetic environments, 12.5% form filling and user interactions, 8.8% grounding, and 4.9% visual question answering, with smaller shares for GUI drag, instruction following and safety scenarios. During training, loss was applied only to the three most recent turns in each trajectory to focus learning on immediate decision steps.
FaraGen1.5 consists of three modular components — environments, solvers and verifiers — designed to mirror realistic web tasks and to produce verifiable training data. Environments split into open‑internet tasks that run on live non‑login sites and gated‑domain tasks that require authentication or irreversible actions. For gated domains the team built six synthetic clones (FaraEnvs) named Mail, Calendar, Stream, ML, Stay and Scheduler, each providing a realistic frontend, a functional API and persona‑based seed data to enable closed‑loop testing with ground truth.
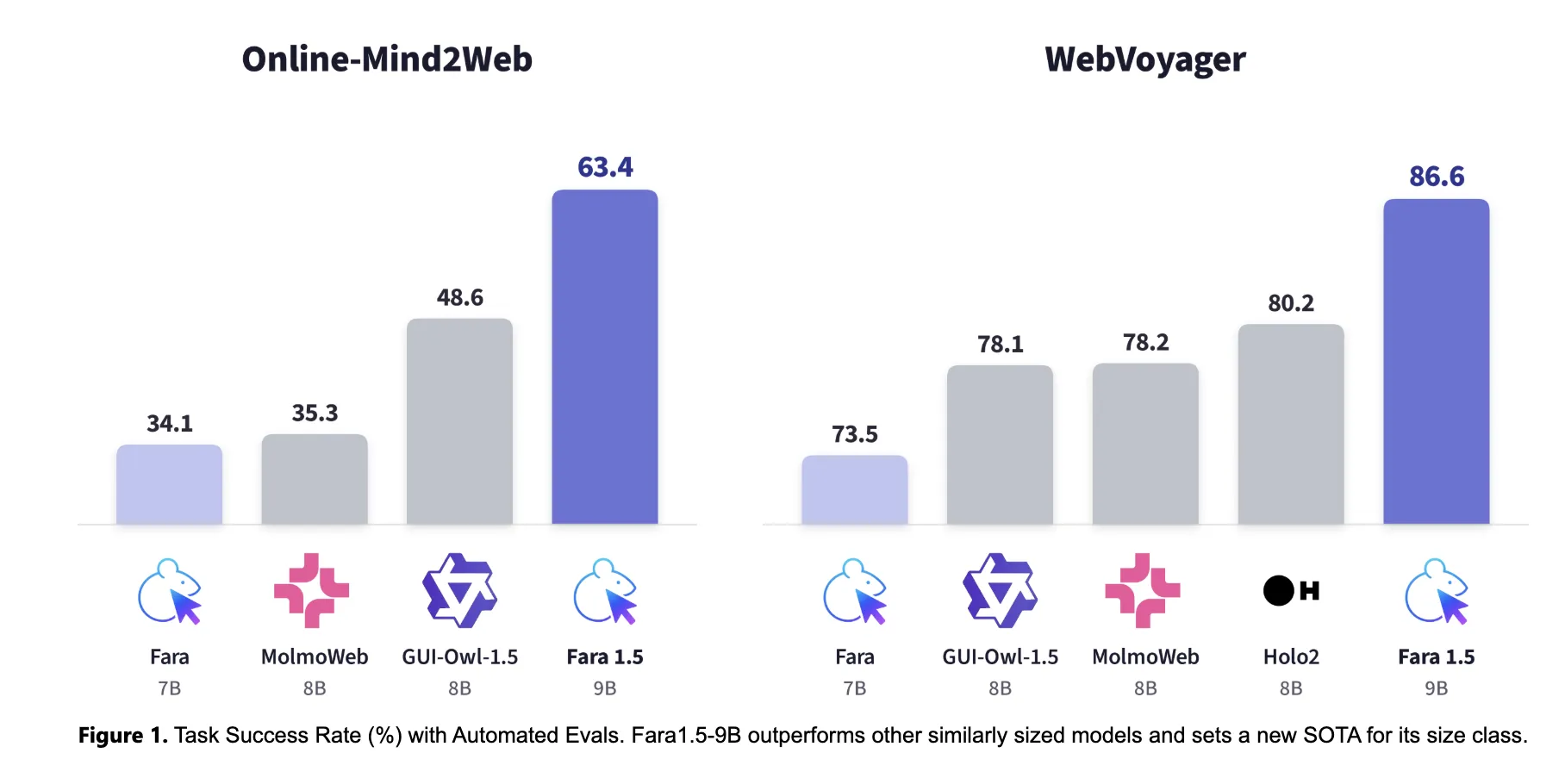
The pipeline’s solver uses OpenAI’s GPT‑5.4 augmented with custom tools that reflect Fara1.5’s action space; evaluated by an automated WebJudge on the Online‑Mind2Web benchmark it scored 83%, up from 67% for the earlier Fara‑7B solver. On the same benchmark and over a separate test of 300 tasks across 136 popular sites, the Fara1.5‑27B model achieved 72% task success. For context, other recent systems scored lower on that comparison: OpenAI’s Operator 58.3%, Google’s Gemini 2.5 Computer Use 57.3%, Yutori’s Navigator n1 64.7%, and Fara1.5‑9B 63.4; the older Fara‑7B had been 34.1.
Safety and verification are integrated throughout the pipeline and the agents. Agents must stop and ask the user in three situations: when tasks require unspecified personal data, when instructions are ambiguous, and before irreversible actions. Trajectories are gated by verifiers that check correctness (using LLM rubrics for open‑internet tasks and privileged database judges for synthetic ones), penalize inefficient action sequences, and validate user‑interaction behavior. The release highlights a complete stack for developers — sandboxed execution, synthetic gated environments with ground truth, database‑level judging, and enforced user‑approval flows for irreversible changes.
Sources
Replies (0)
No replies in this topic yet.