Microsoft Research’s AI Frontiers lab has released Webwright, an open-source, terminal — native framework that lets large language model agents write and execute Playwright scripts and shell commands to automate browsers. By treating the browser as a disposable runtime and keeping code, logs and artifacts as the persistent workspace, Webwright moves web automation from click — by-click interaction to reproducible, inspectable programs — making iterative debugging and long-horizon workflows easier to manage.
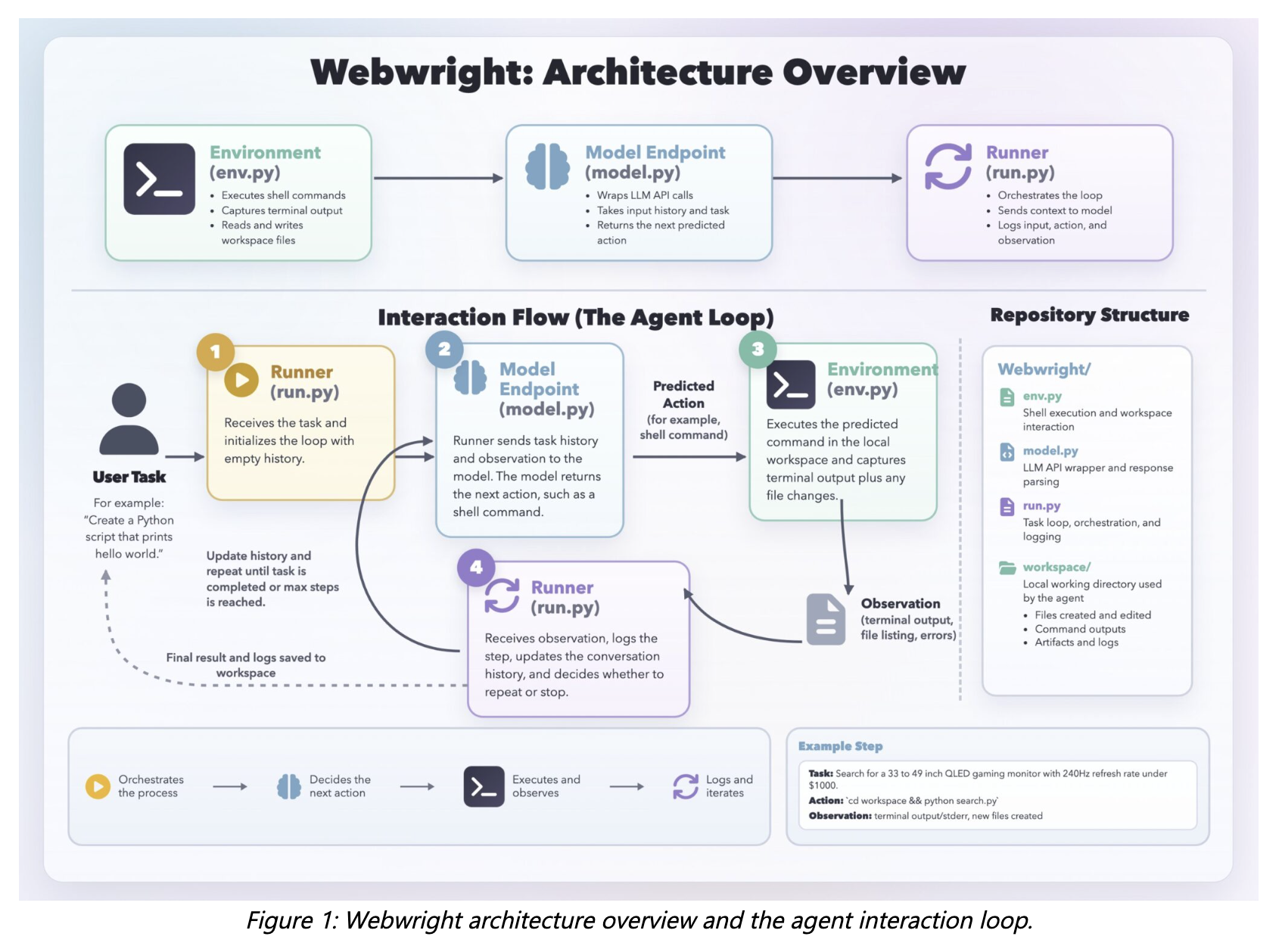
The implementation centers on three compact components: a Runner (about 150 lines of code), a Model Endpoint or interface (roughly 550 lines) and a terminal Environment (around 300 lines), totaling about 1,000 lines. Agents generate Playwright code-which can programmatically control Chromium, Firefox and WebKit — execute it, capture logs and screenshots, and store every intermediate script and artifact in the workspace for review and reruns.
Webwright’s agent loop departs from primitive action prediction. The Runner sends the current context to the model; the model replies with a thinking block and a shell command; the Environment executes that command and returns terminal output, logs, screenshots or error tracebacks; those observations reenter the context and the loop repeats. This design encourages agents to emit multi — step programs — loops, functions and abstractions — rather than one-off click or keypress actions.
Two engineering guardrails address practical failure modes. To avoid premature “done” signals, Webwright requires agents to produce a self-reflection configuration, run a final script in a fresh folder that includes logs and screenshots, and pass an internal self-reflection check before emitting done:true; runs that fail the check are retried. To control context growth during long coding trajectories, Webwright compacts history every 20 steps into a single summary.
Microsoft evaluated Webwright on two public benchmarks. On Online — Mind2Web (300 tasks across 136 sites, judged by AutoEval with a 100 — step budget), GPT-5.4 in the Webwright harness reached 86.67% overall accuracy — the highest AutoEval score reported among open-sourced harness recipes — while Claude Opus 4.7 reached 84.7% overall and outperformed GPT-5.4 on hard tasks at N=100 (80.5% vs 76.6%). On the long-horizon Odysseys benchmark, Webwright with GPT-5.4 scored 60.1%, up from a screenshot — based baseline using the same model at 33.5%, and showed substantial gains across all three difficulty categories versus coordinate — prediction agents.
For builders, Webwright converts web automation into reusable, inspectable Playwright programs that can be rerun, adapted and shared, simplifying debugging and iteration for complex tasks. The single — agent loop minimizes orchestration, but teams should adopt the framework’s self-reflection gate and history compaction techniques as guardrails to prevent false completion signals and manage context length.
Sources
Replies (0)
No replies in this topic yet.