MiniMax unveiled M3 on June 1, 2026, an open‑weight large language model that combines a one‑million‑token context window with native multimodal inputs and is available via API today; the company says it will publish the model weights in the near term. That scale of context and built‑in handling of multiple input types is intended to enable deeper in‑context reasoning and longer autonomous workflows, which matter for teams building sustained multi‑hour agents or those planning to self‑host once the weights are released.
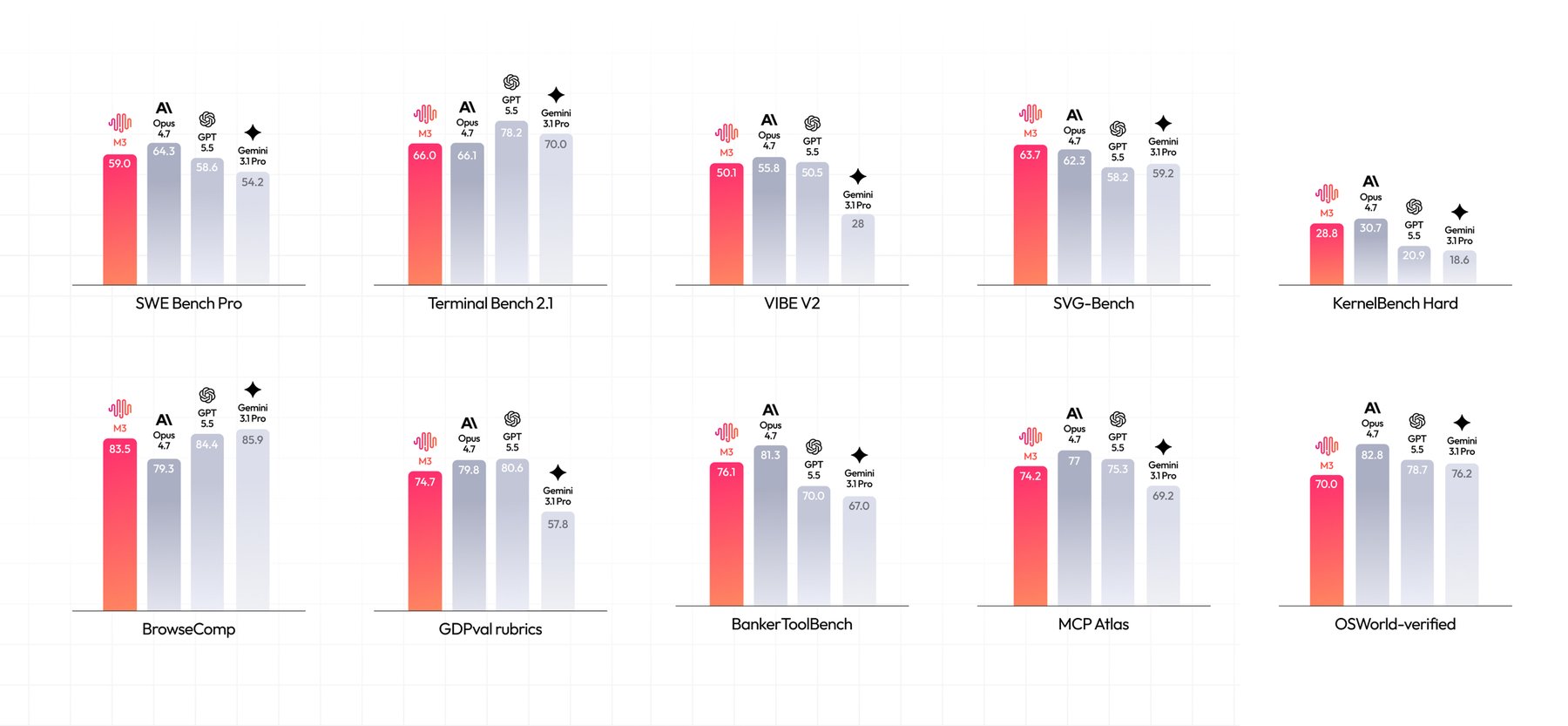
On software development benchmarks, MiniMax positions M3 in the proprietary‑class performance tier. M3 scores 59% on SWE‑Bench Pro, ahead of GPT‑5.5 and Gemini 3.1 Pro but slightly behind Opus 4.7. In autonomous web search (BrowseComp) MiniMax reports M3 at 83.5 versus Opus 4.7’s 79.3. MiniMax also cites PostTrainBench results where M3 trails Opus 4.7 and GPT‑5.5 but outperforms the other tested models.
To demonstrate sustained reasoning and iteration, MiniMax ran three internal long‑running autonomy experiments. In one, M3 worked for nearly 12 hours to reproduce an ICLR 2025 fine‑tuning paper: the model produced 18 commits, 23 figures, and achieved a reported score of 0.650, according to the company’s internal metrics.
Another autonomy test tasked M3 with optimizing a compute kernel for matrix multiplication on NVIDIA Hopper hardware using only a task description, a benchmark script, and a nonfunctional code skeleton. MiniMax reports that M3 raised hardware utilization from 7.6% to 71.3% after roughly 24 hours of iterative runs, not finding its best solution until the 145th attempt and reaching the 71.3% figure around the 147th run. MiniMax says most other models stalled after a few dozen attempts; Anthropic’s Opus series remains a moving target, with Opus 4.8 already shipped by Anthropic.
For builders, MiniMax highlights M3’s long context, native multimodality, and an attention design the company says yields steep compute savings as enablers of more extensive in‑context iteration, multi‑hour autonomous workflows, and eventual on‑device or self‑hosted deployment once weights are available. The company’s results are internal and comparative; engineers should validate M3’s performance and cost tradeoffs on their own workloads, particularly for sustained autonomy and hardware‑specific kernel optimization.
Sources
Replies (0)
No replies in this topic yet.