Mistral has released Voxtral TTS, its first text-to-speech model, publishing open weights on Hugging Face and providing a hosted API. The company describes Voxtral as a purpose — built architecture intended to close the “Expressivity Gap,” the difference between intelligible TTS and naturally expressive, speaker — faithful speech, by combining distinct modeling approaches for linguistic content and fine acoustic detail.
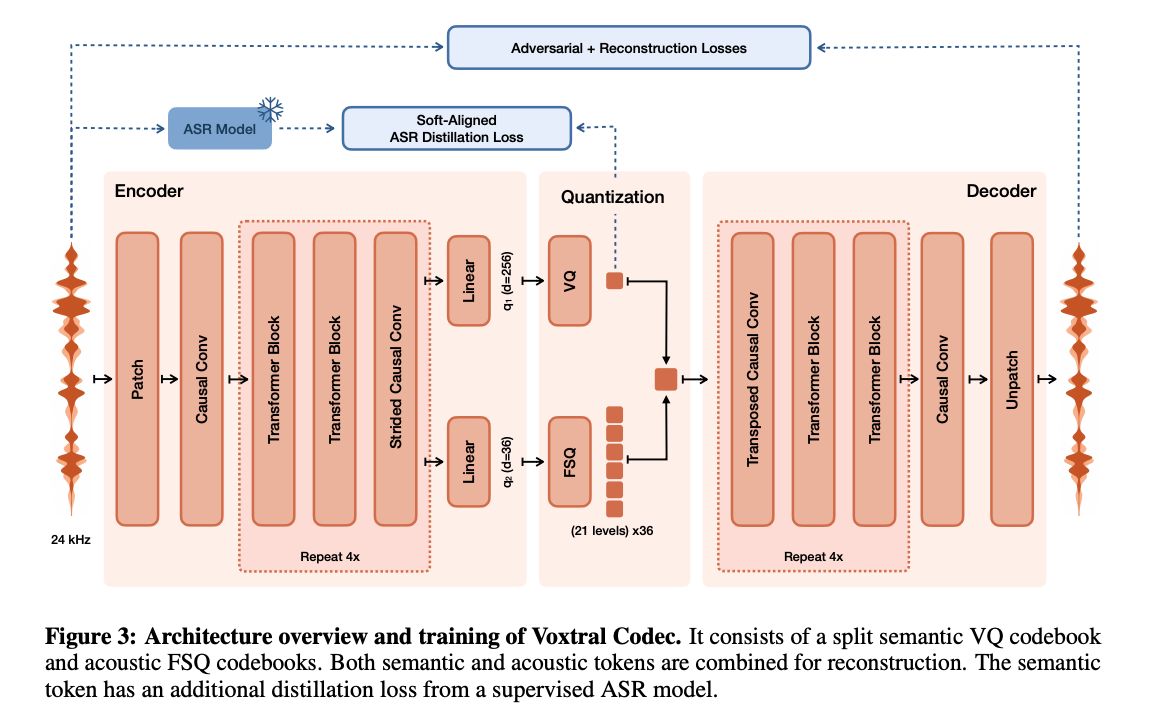
At the front end is the Voxtral Codec, which tokenizes 24 kHz mono waveforms into frames at 12.5 Hz (one frame every 80 ms). Each frame yields 37 discrete tokens: a single semantic token produced by vector quantization with an 8,192 — entry codebook, plus 36 acoustic tokens obtained via finite scalar quantization at 21 levels. The codec operates at roughly 2.14 kbps, and the semantic token training uses distillation targets derived from a frozen Whisper ASR model.
The full system totals roughly 4 billion parameters split across three components: a 3.4B autoregressive decoder backbone initialized from Ministral 3B, a 390M flow-matching acoustic transformer, and a 300M neural audio codec. During inference, audio tokens drawn from a reference clip are prepended to the text input; the autoregressive decoder then generates one semantic token per 80 ms frame until a dedicated end-of-audio token, while the flow module produces the fine-grained acoustic tokens that the codec decodes back into waveform.
Mistral reports that Voxtral produces natural, speaker — faithful speech in nine languages from reference clips as short as three seconds. In multilingual voice — cloning evaluations conducted with native — speaker annotators, Voxtral achieved a 68.4% win rate against ElevenLabs Flash v2.5. On low-bitrate codec benchmarks (Expresso), the Voxtral Codec outperformed Mimi (the Moshi codec) across objective measures including Mel distance, STFT distance, PESQ, ESTOI, ASR word-error rate and speaker similarity.
The company also published deployment performance numbers to clarify engineering tradeoffs: a single NVIDIA H200 can serve more than 30 concurrent users at sub-600 ms latency, offering a practical reference point for cost and latency planning in use cases such as voice agents, audiobooks, or multilingual support pipelines. The hybrid design explicitly separates semantic and acoustic modeling to avoid the compromises that result when a single approach attempts both tasks.
For builders the release provides both open models and a managed API to test integration paths: short — reference cloning (3 — 30 seconds), multilingual outputs, and a stated route to maintain long-range speaker coherence while preserving fine acoustic texture via the flow component. Those elements position Voxtral as both a research milestone and a concrete starting point for production TTS experiments.
Sources
Replies (0)
No replies in this topic yet.