Lighthouse Attention is a training‑only, selection‑based hierarchical wrapper that pools Q, K and V into a multi‑resolution pyramid, picks a compact dense subsequence, and runs standard FlashAttention on that block to accelerate long‑context pretraining.
Nous Research has introduced Lighthouse Attention, a training‑time wrapper that speeds scaled dot‑product attention (SDPA) for very long sequences by selecting a compact dense subsequence and running ordinary dense attention on it. Applied only during pretraining and removed at inference, the method produced a 1.40–1.69× wall‑clock speedup in reported experiments while reaching matching or lower final training loss, allowing the final model to retain standard dense attention without extra selection machinery.
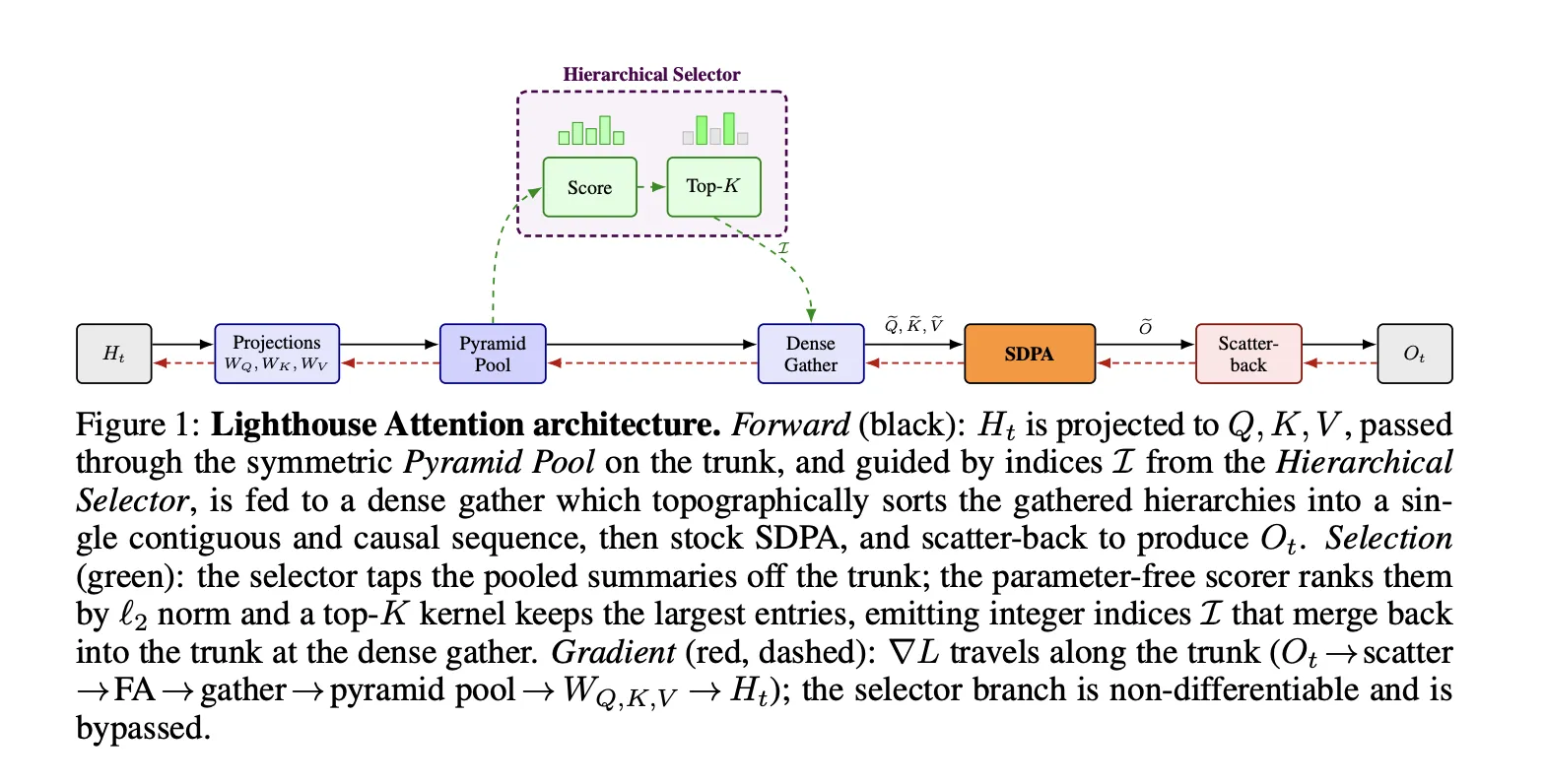
The method constructs an L‑level, symmetric pyramid by average pooling queries (Q), keys (K) and values (V); pyramid construction costs Θ(N) time and memory. After pooling, Lighthouse uses a discrete selection stage to gather a small subset of entries into a contiguous subsequence, then invokes stock FlashAttention (a dense SDPA kernel) on that compact block. The paper frames this as an asymptotic change in the attention call from O(N·S·d) to O(S²·d), shifting the dominant computation to highly optimized dense kernels.
Selection proceeds in four stages. First, Q, K and V are pooled into the pyramid. Second, a parameter‑free scorer computes per‑head L2 norms to produce query and key scores. Third, a fused chunked‑bitonic top‑K jointly selects k indices across levels while fully retaining the coarsest level; this chunked, stratified top‑K is designed to avoid collapse onto narrow spans. Fourth, Lighthouse gathers the chosen indices into a contiguous block and runs dense SDPA on that block.
The top‑K selection is discrete and non‑differentiable: indices carry no gradient and there is no straight‑through estimator or Gumbel softmax. Gradients flow only through the gathered Q, K and V back into the projection matrices WQ, WK and WV, so the projections learn to produce entries that become useful when selected rather than directly learning selection scores.
In experiments the team pretrained a 530M Llama‑3‑style model with a 98K context window and compared end‑to‑end wall‑clock pretraining time against a cuDNN‑backed SDPA baseline. Lighthouse delivered a 1.40–1.69× speedup while matching or improving final training loss, demonstrating practical gains for extremely long contexts in an end‑to‑end setup. Lighthouse differs from prior sparse attention schemes (NSA, HISA, DSA, MoBA) that typically compress only K and V or embed selection inside custom kernels. By pooling Q, K and V symmetrically and performing selection outside the attention kernel, Lighthouse lets practitioners reuse heavily optimized dense kernels (FlashAttention), simplifying engineering and preserving a dense‑attention model at inference.
Sources
Replies (0)
No replies in this topic yet.