Nous Research published Token Superposition Training (TST), a two‑phase pre‑training procedure that shortens wall‑clock LLM pre‑training time at fixed FLOPs while preserving final model architecture and next‑token inference behavior. The team reports up to a 2.5× reduction in total pre‑training time on evaluated scales, a change that can materially cut GPU hours for large model builders without altering inference dynamics.
TST’s first stage, the Superposition Phase, replaces individual token inputs with contiguous “bags” of s tokens: each bag is averaged into a single latent embedding so the transformer processes sequences shortened by a factor of s. To keep per‑step FLOPs equal to standard training, the procedure increases sequence throughput, and the model predicts the next bag using a multi‑hot cross‑entropy (MCE) loss that assigns equal 1/s mass to each token in the target bag.
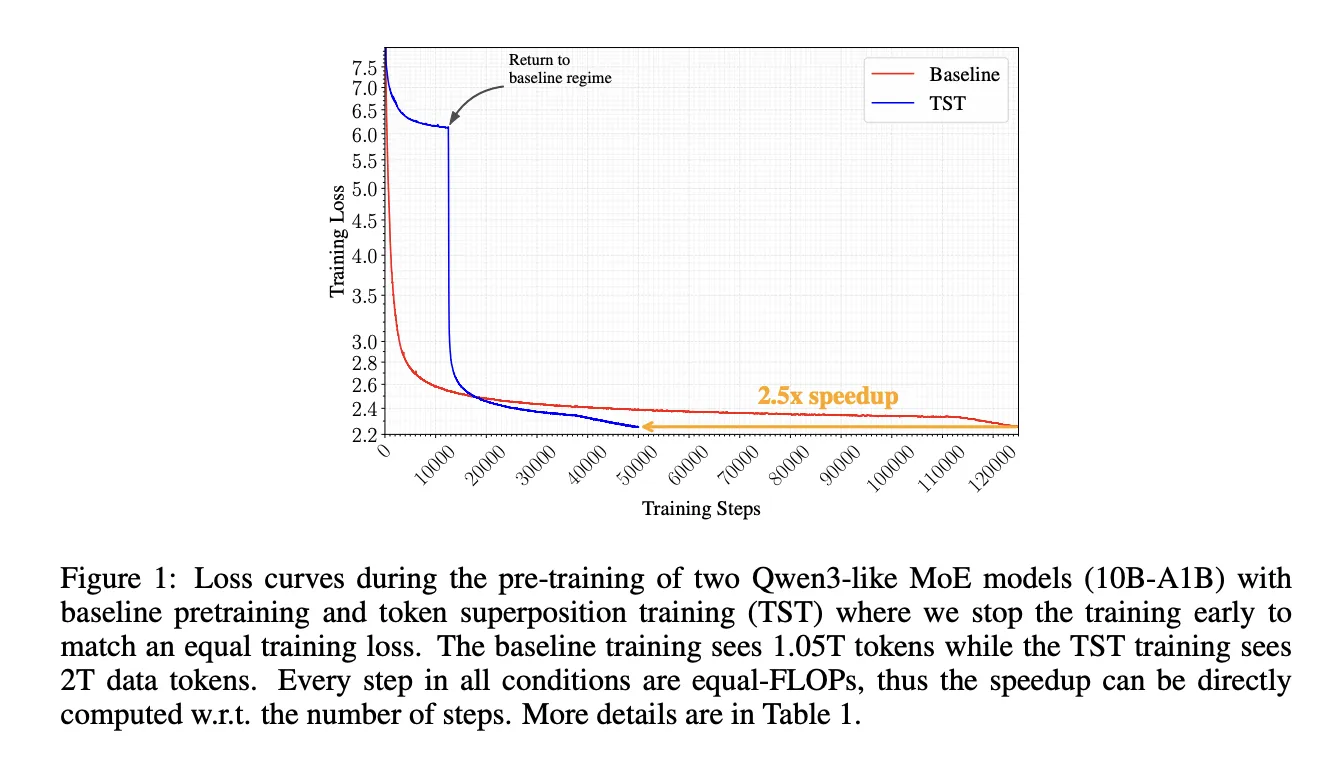
After the Superposition Phase TST switches to a Recovery Phase that resumes ordinary next‑token prediction for the remainder of training. The TST code is removed at the phase boundary; a transient loss spike of roughly 1–2 nats appears at the transition and typically resolves within a few thousand steps, after which the recovered checkpoint drops below the equal‑FLOPs baseline loss.
Nous validated TST across four model scales: 270M and 600M dense models (SmolLM2 shapes adapted to Llama3 modeling code with the Llama3‑8B tokenizer and untied input/output embeddings), a 3B dense SmolLM3 shape, and a 10B A1B Mixture‑of‑Experts model in the Qwen3 family. Small runs used 8 NVIDIA B200 GPUs; larger experiments used 64 B200 GPUs. Training used AdamW with a Warmup‑Stable‑Decay learning‑rate schedule under TorchTitan with FSDP.
In the 10B A1B MoE experiment TST consumed 4,768 B200 GPU‑hours versus the baseline’s 12,311 GPU‑hours — roughly a 2.5× reduction — and produced a lower final training loss than a matched‑FLOPs baseline. At 3B scale, a TST run with bag size s = 6 and superposition step fraction r = 0.3 reached a final loss of 2.676 at 20,000 steps, illustrating protocol‑scale gains across the 270M to 10B parameter regimes.
The method is deliberately compatible with existing training stacks: it requires no changes to model architecture, tokenizer, optimizer, parallelism strategy, or training data, and MCE can be implemented using existing fused cross‑entropy kernels without new fused ops or auxiliary heads. Nous recommends superposition fractions r in the range [0.2, 0.4] and demonstrates practical bag sizes such as s = 6 in experiments, offering a drop‑in option for builders seeking to cut wall‑clock pre‑training time.
Sources
Replies (0)
No replies in this topic yet.