Nous Research has introduced Contrastive Neuron Attribution (CNA), a forward‑only method that locates a tiny fraction of MLP neurons whose activations discriminate harmful from benign prompts and uses simple intervention at inference to change model refusals. Ablating roughly 0.1% of MLP activations cut refusal rates by more than half in most instruction‑tuned models the team tested — covering Llama and Qwen families from 1B to 72B parameters — while maintaining output‑quality metrics and general capability benchmarks. This gives builders and auditors a low‑cost, non‑invasive probe and steering tool for aligned models.
CNA finds neurons via contrastive mean activations computed at the final token for the down‑projection at each MLP layer. For neuron j in layer ℓ the method records δ_j^ℓ = mean_activation(positive prompts) − mean_activation(negative prompts), ranks neurons by |δ| across layers, and selects the top k (the authors use k = 0.1% of total MLP activations). A post‑filter removes ‘universal’ neurons that appear in the top 0.1% across at least 80% of diverse prompt contrasts to avoid overly broad effects.
The pipeline requires only forward passes — no gradients, no sparse autoencoder (SAE) training, no auxiliary loss, and no weight modification or iterative search. Causality is evaluated at inference by scaling each discovered neuron's activation with a multiplier m (m = 0 to ablate, m = 1 baseline, m >1 to amplify). Discovery used a 100/100 harmful/benign prompt set for the main JBB — Behaviors evaluation, with smaller 8/8 sets for qualitative examples and other tasks.
Evaluation spanned 16 models: base and instruction variants of Llama 3.1/3.2 and Qwen 2.5 across 1B-72B parameters, using the JBB — Behaviors (NeurIPS 2024) benchmark of 100 harmful prompts as the primary test. Selected results include dramatic drops in refusal rates after ablating the top 0.1% neurons: Llama‑3.1 70B‑Instruct fell from 86% to 18% (−79.1%); Qwen2.5 7B‑Instruct from 87% to 2% (−97.7%); Qwen2.5 72B‑Instruct from 78% to 8% (−89.7%). Smaller models showed smaller relative declines — for example, Llama‑3.2 3B‑Instruct dropped from 84% to 47%.
Compared with other steering techniques, CNA is more surgical and less disruptive. Contrastive Activation Addition (CAA), which applies layer‑wide residual differences, can produce degraded or repetitive output at high steering strengths — CAA fell below 0.60 on the paper’s output‑quality metric in six of eight instruct models at maximum strength. Sparse autoencoders require expensive external training and are noise‑sensitive. By contrast, CNA preserved output quality (measured as 1 minus the fraction of repeated n‑grams) above 0.97 across all steering strengths tested.
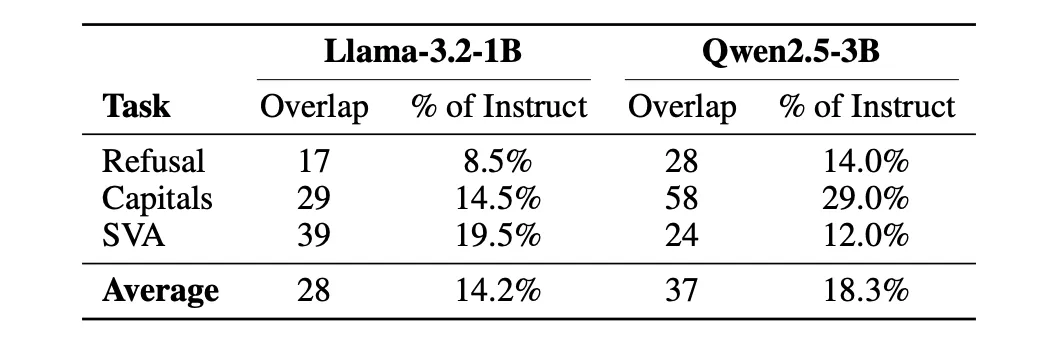
Beyond a practical steering tool, the authors make an interpretability claim with alignment implications: the refusal‑discriminating structure appears in base models prior to alignment fine‑tuning, and alignment tuning repurposes neurons within that pre‑existing structure rather than creating entirely new circuits. The paper notes that CNA’s discoveries depend on the chosen prompt contrasts, the 0.1% selection threshold, and the universal‑neuron filtering, so results may vary with those design choices.
Sources
Replies (0)
No replies in this topic yet.