NVIDIA has published Gated DeltaNet-2, a recurrent linear‑attention layer and Transformer block that explicitly separates memory erase and write controls by using channel‑wise gates. A reported 1.3B‑parameter variant trained on 100B FineWeb‑Edu tokens outperformed Mamba‑2, Gated DeltaNet, KDA and Mamba‑3 across language modeling, commonsense reasoning and long‑context retrieval benchmarks, with the largest gains on RULER S‑NIAH and a multi‑key needle retrieval task. That performance positions the model as a candidate for tasks that require efficient long‑context handling and less destructive memory edits.
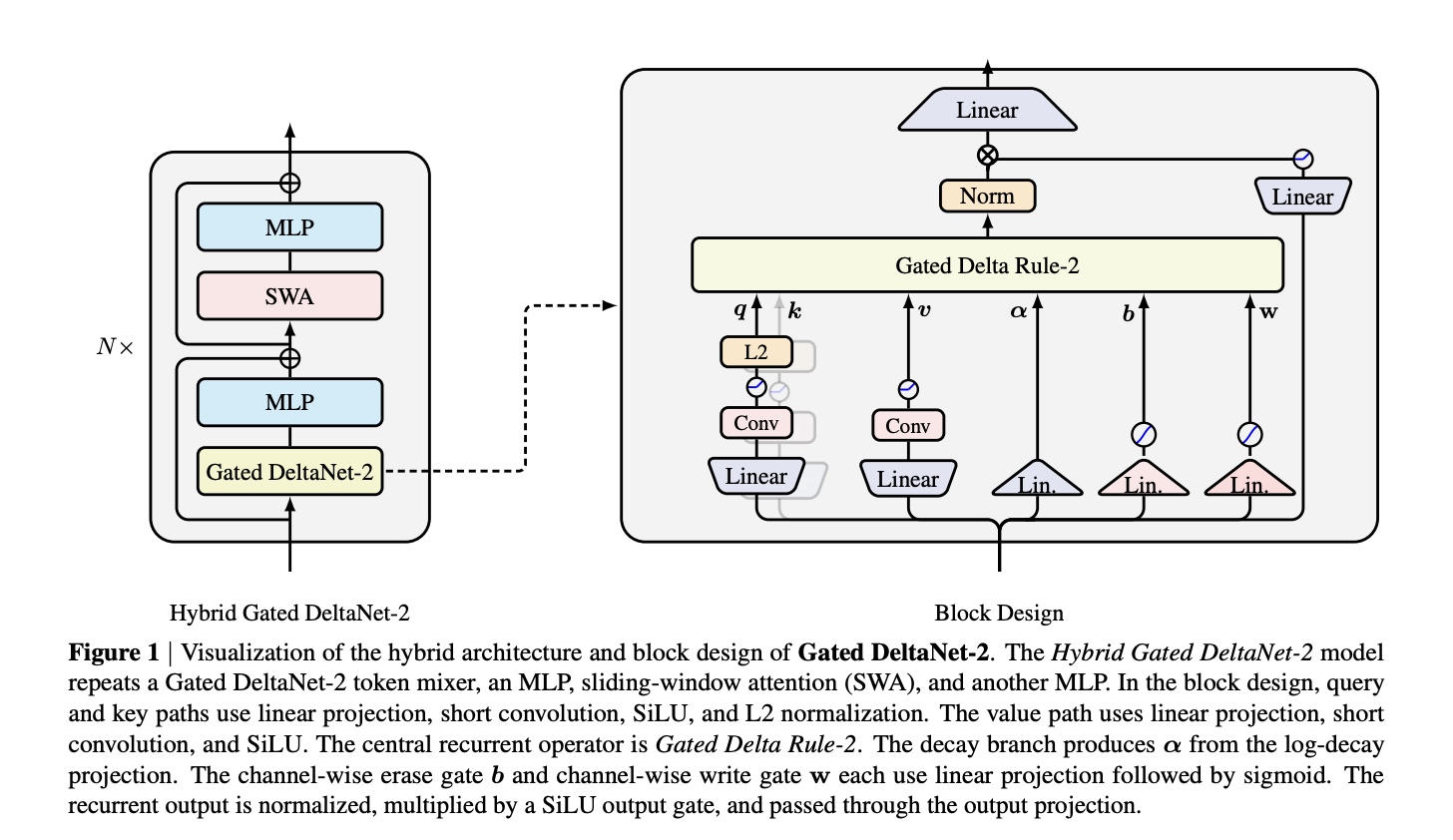
The central algorithmic change is a split of editing operations into an erase gate b_t applied on the key axis and a write gate w_t applied on the value axis, both produced by sigmoid projections of token representations; channel‑wise decay D_t = Diag(α_t) from KDA is retained. The authors present the recurrence compactly as S_t = (I − k_t (b_t ⊙ k_t)ᵀ) D_t S_{t−1} + k_t (w_t ⊙ v_t)ᵀ, which makes reads and writes selective across channels rather than controlled by a single scalar.
Gated DeltaNet‑2 targets a modeling restriction in prior delta‑rule families that used a single scalar to govern both erasure and commit. KDA introduced channel‑wise decay but kept an active scalar edit step; earlier Gated DeltaNet tied decay and edit into scalar subspaces. The new design recovers KDA and Gated DeltaNet as special cases when its gates collapse to scalars, while enabling distinct per‑channel decisions that can align differently with the recurrent state's axes.
On the systems side the recurrence admits a chunkwise WY formulation compatible with KDA‑style training. The implementation uses a chunk size C = 64 and fused Triton kernels for the forward pass. Backpropagation requires gate‑aware vector — Jacobian products because erase and write factors carry separate diagonal gates; to support this the fused WY backward kernel was implemented with two‑ and four‑warp layouts on Hopper GPUs to avoid a Triton WGMMA layout assertion.
The model block remains plug‑compatible with Transformer stacks: query and key paths use linear projection, a short causal convolution, SiLU activations and L2 normalization; values use linear projection, short convolution and SiLU. Separate linear branches emit the decay α_t plus the erase b_t and write w_t gates. The authors also describe a fast‑weight interpretation in which the update acts like an online gradient step on a local regression loss, keeping the decayed state close to memory while applying a gated residual edit.
For builders, the reported gains matter in scenarios that compress the unbounded KV cache into a fixed recurrent state: linear attention yields linear‑time sequence mixing and constant‑memory decoding, and Gated DeltaNet‑2 aims to make edits to that compressed memory less destructive. The paper and implementation are provided in the project repository for inspection and integration.
Sources
Replies (0)
No replies in this topic yet.