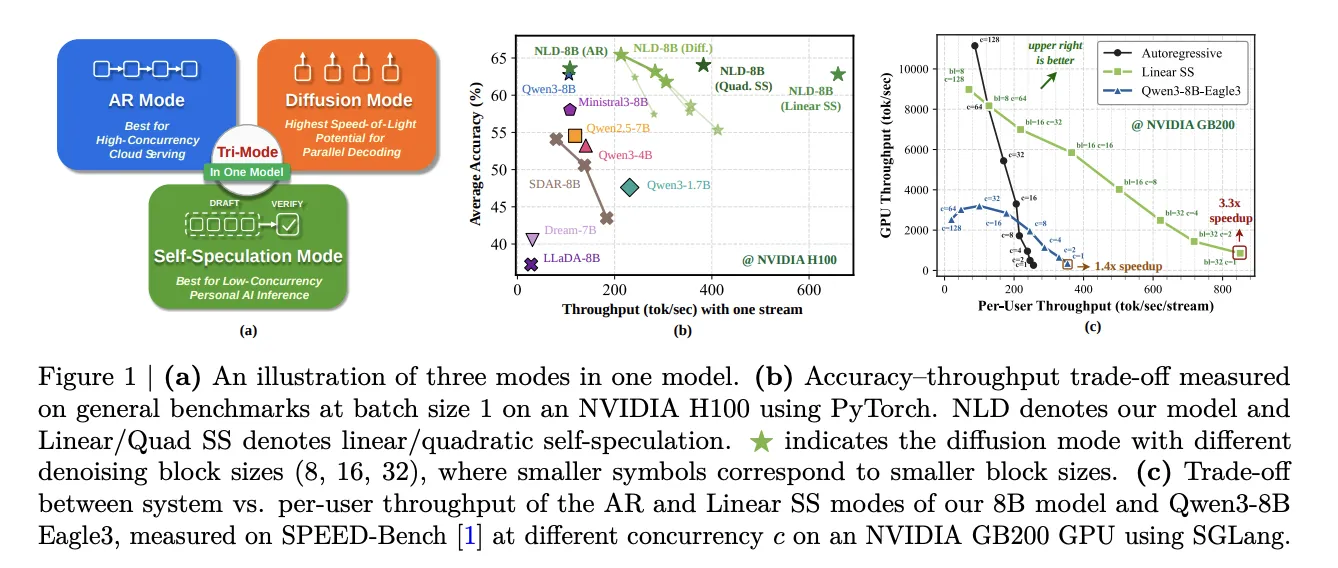
NVIDIA has released Nemotron — Labs-Diffusion, a family of language models that runs three decoding modes from a single set of weights — standard left-to-right autoregressive (AR) decoding, diffusion — based parallel denoising, and a hybrid self-speculation mode-and reports up to 6× tokens per forward pass versus Qwen3 — 8B. That throughput improvement targets scenarios where sequential AR decoding underutilizes GPUs, such as low-batch cloud inference and edge deployments. The Nemotron family includes 3B, 8B and 14B parameter models, offered in base, instruct and vision — language variants. All variants use the same transformer weights across modes, so a single checkpoint supports AR, diffusion and self-speculation decoding without mode-specific architectural forks.
Nemotron is trained on a joint AR-diffusion objective but preserves a single shared architecture. In AR mode it performs standard causal — attention, left-to-right generation. In diffusion mode the model partitions a sequence into contiguous fixed — length blocks: tokens attend bidirectionally inside each block while attention remains causal across blocks to permit reuse of KV caches for prior blocks. A lightweight trained sampler predicts which masked positions can be committed at each denoising step, allowing multiple committed tokens per forward pass.
Self-speculation uses the diffusion pathway to draft k candidate tokens in parallel and then runs the AR pathway within the same model as a verifier. The AR pass verifies the longest contiguous prefix that matches its expectations; each self-speculation cycle thus yields between 1 and k+1 verified tokens. Unlike Multi — Token Prediction (MTP) approaches such as Eagle3, which add auxiliary draft heads to an AR backbone, Nemotron requires no separate draft model or extra prediction head.
Training combines an AR next-token loss with a block — wise diffusion denoising loss: L(θ) = L_AR(θ) + α · L_diff(θ). NVIDIA sets α = 0.3 across stages and reports ablations sweeping α from 0.1–1.0 that peak at 0.3 without trading off one mode for the other. The training pipeline is two-stage: an AR-only stage over 1 trillion tokens to establish left-to-right priors, followed by 300 billion tokens of joint AR-diffusion training. Ablations credited two-stage training with +5.74% average accuracy, adding the AR loss with +7.48%, global loss averaging with +2.12%, and a cumulative +16.05% average accuracy improvement.
The report highlights deployment trade — offs: AR mode remains the best fit for high-concurrency cloud serving, while diffusion and self-speculation boost per-forward throughput for low-batch or edge scenarios where sequential AR decoding yields poor GPU utilization. The across — block causal attention pattern is an explicit engineering choice to balance parallel denoising against reuse of previous computation, and it has concrete effects on latency and memory behavior in multi — block generation.
Sources
Replies (0)
No replies in this topic yet.