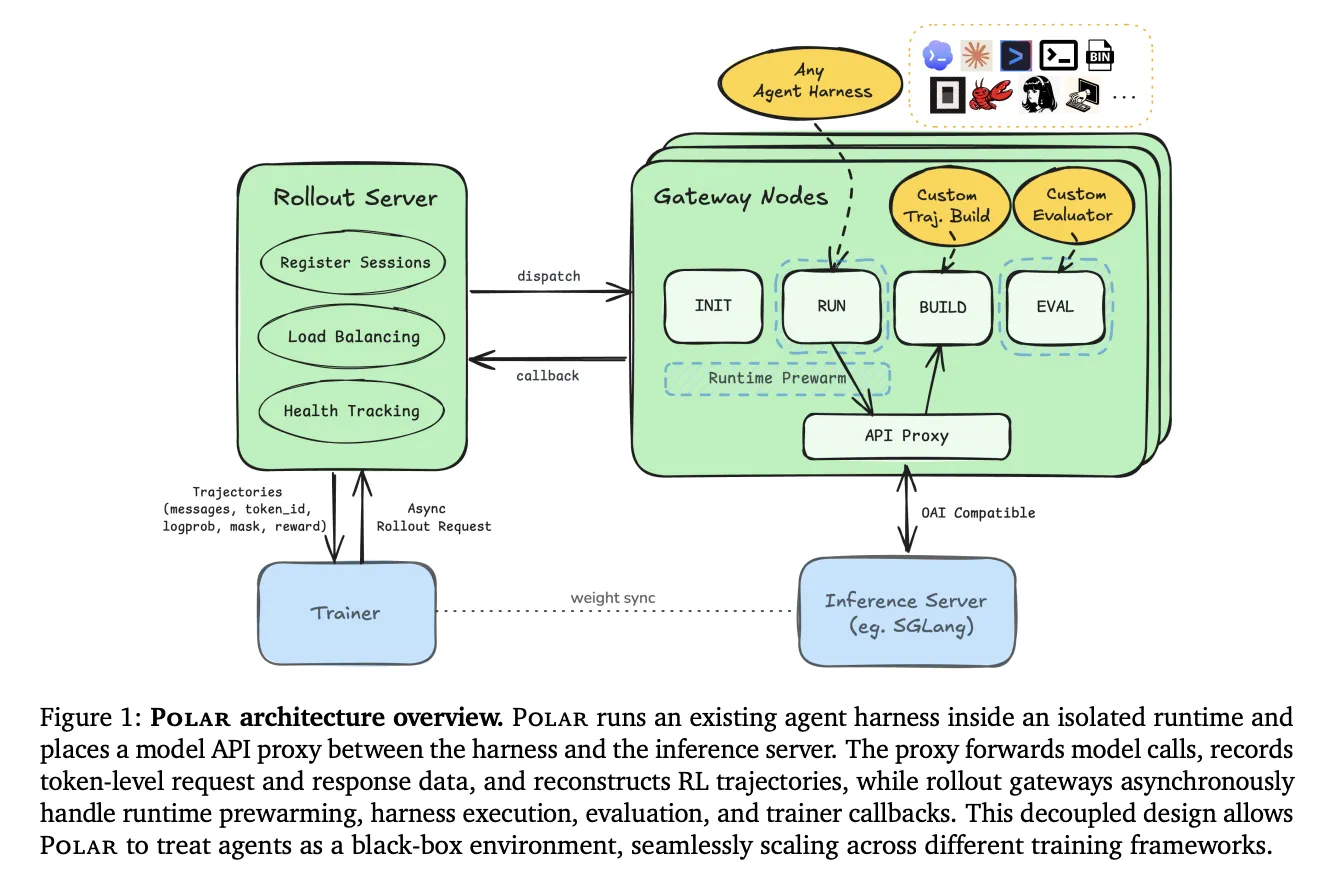
NVIDIA researchers have published Polar, a proxy‑first rollout framework that captures token‑level interactions at the model API boundary so reinforcement learning (GRPO) can be applied to existing language‑agent harnesses without rewriting their control flow. By recording exact prompt and sampled token IDs plus relevant metadata, Polar enables training infrastructure to reconstruct trajectories that reflect a harness’s native behavior — letting teams train against off‑the‑shelf harnesses instead of instrumenting them.
Polar implements a gateway proxy placed between a harness and an inference server and processes each model request in four steps: detect the provider API (for example Anthropic messages, OpenAI chat/responses, or Google generateContent style), normalize inputs into an OpenAI chat‑completions shape, capture prompt and sampled response token IDs along with metadata such as finish reasons and logprobs, and transform the response back into the harness’s expected schema. For streaming calls, Polar synthesizes provider‑shaped streams from non‑streaming upstream responses so harnesses receive familiar stream semantics.
The only change required to a harness is directing its model base URL to Polar’s gateway. The project is packaged as a NeMo Gym environment and published in the ProRL Agent Server repository, reducing per‑harness engineering work for researchers who want to run RL over existing agent setups.
Polar’s runtime separates a central rollout server from gateway nodes. The rollout server expands TaskRequests into independent sessions and dispatches them; gateway nodes start runtimes, run the harness, host a per‑session proxy, assemble trajectories, run evaluators, and tear down sessions. Gateways use isolated worker pools for INIT, RUNNING, and POSTRUN stages and maintain a bounded READY buffer so CPU‑heavy preparation and evaluator prewarm do not block GPU‑bound agent execution. If a harness times out after model calls have been captured, Polar still enters POSTRUN so partial traces can be recovered.
Built‑in evaluators include session‑completion rewards, configurable test‑on‑output checks, and a SWE‑Bench / SWE‑Gym harness evaluator, and a registry supports custom evaluators. Polar currently supports Docker and rootless Apptainer runtimes and provides built‑in harness shortcuts for codex, claude_code, gemini_cli, qwen_code, opencode, and pi to reduce integration work.
Sources
Replies (0)
No replies in this topic yet.