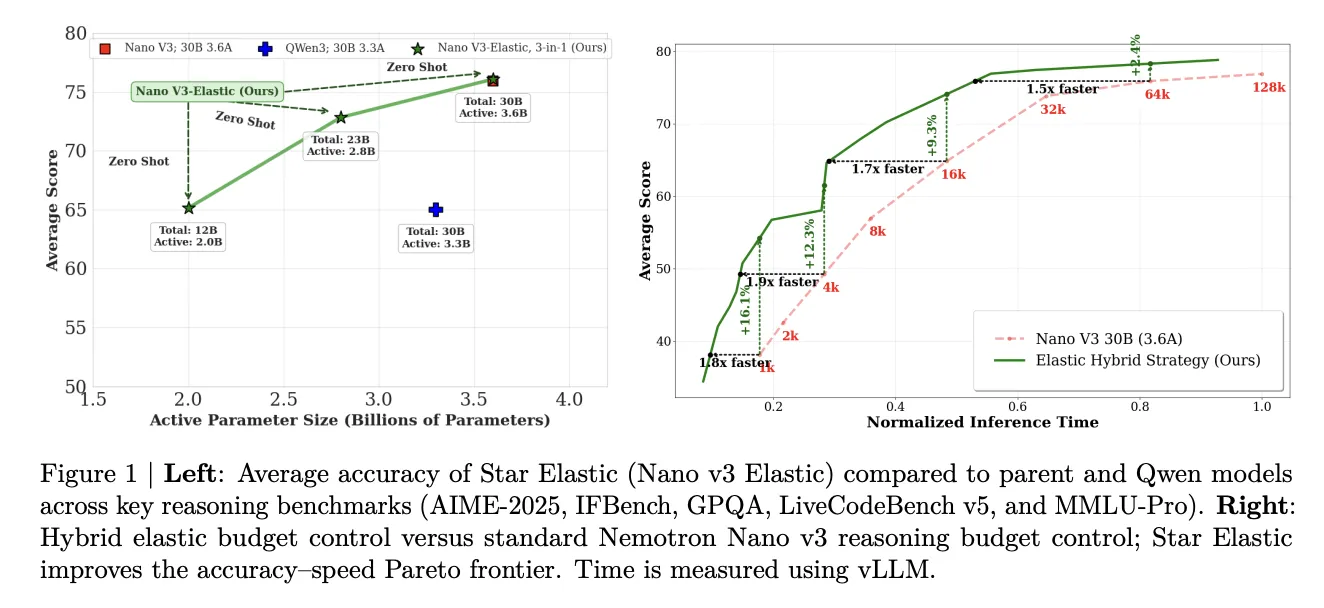
NVIDIA has unveiled Star Elastic, a post‑training technique that embeds multiple nested reasoning models — at 30B, 23B and 12B parameter scales — inside a single parent checkpoint, eliminating the need for separate full pretraining runs or distinct stored weights for each size. That design cuts cumulative pretraining token cost by roughly 360× compared with pretraining each model from scratch and allows teams to extract smaller, ready‑to‑run submodels without additional fine‑tuning.
The team implemented Star Elastic on the Nemotron Elastic framework and applied it to Nemotron Nano v3, a hybrid Mamba — Transformer–MoE model with 30B total parameters and 3.6B active parameters. From a single ~160B‑token training run the method produces nested 23B (2.8B active) and 12B (2.0B active) variants; all three variants reside in one checkpoint and are available without extra post‑training.
Star Elastic ranks and selects components — embedding channels, attention heads, Mamba SSM heads, MoE experts and FFN channels — by importance so smaller compute budgets reuse the highest‑ranked contiguous subsets, a nested weight‑sharing strategy that avoids storing separate weights per size. masks via Gumbel‑Softmax.
The technique also proposes elastic budget control at inference: a reduced submodel can handle the intermediate or “thinking” phase while the full parent model produces the final answer, aiming to lower inference cost for some workloads. If adopted, Star Elastic could simplify model management, cut cumulative pretraining tokens and enable dynamic compute budgeting for deployments, though practical gains will depend on downstream tasks and integration effort.
Sources
Replies (0)
No replies in this topic yet.