NVIDIA introduced X‑Token, a logit‑distribution method for cross‑tokenizer knowledge distillation that the team says fixes two structural failures in GOLD and lifts GSM8k accuracy from 2.56% to 15.54%, outperforming GOLD by an average of 3.
NVIDIA has introduced X‑Token, a cross‑tokenizer knowledge‑distillation (KD) method that the researchers say outperforms the prior state of the art — GOLD—by 3.82 average points on Llama‑3.2‑1B and raises GSM8k accuracy from 2.56% to 15.54%. The breakthrough matters because it addresses a practical bottleneck in distillation: standard per‑position KL‑divergence KD requires a shared tokenizer, preventing practitioners from using stronger teacher models that employ different tokenizers.
Traditional KD that minimizes per‑position Kullback‑Leibler (KL) divergence trains a student on the teacher’s full next‑token probability distribution, not just the correct answers. That formulation depends on token positions aligning across vocabularies, so a student fixed to Llama‑3.2‑1B’s tokenizer cannot directly learn from teachers whose tokenizers fragment text differently — examples cited include Phi‑4‑mini and Qwen3‑4B-nor can it easily combine multiple teachers from different tokenizer families.
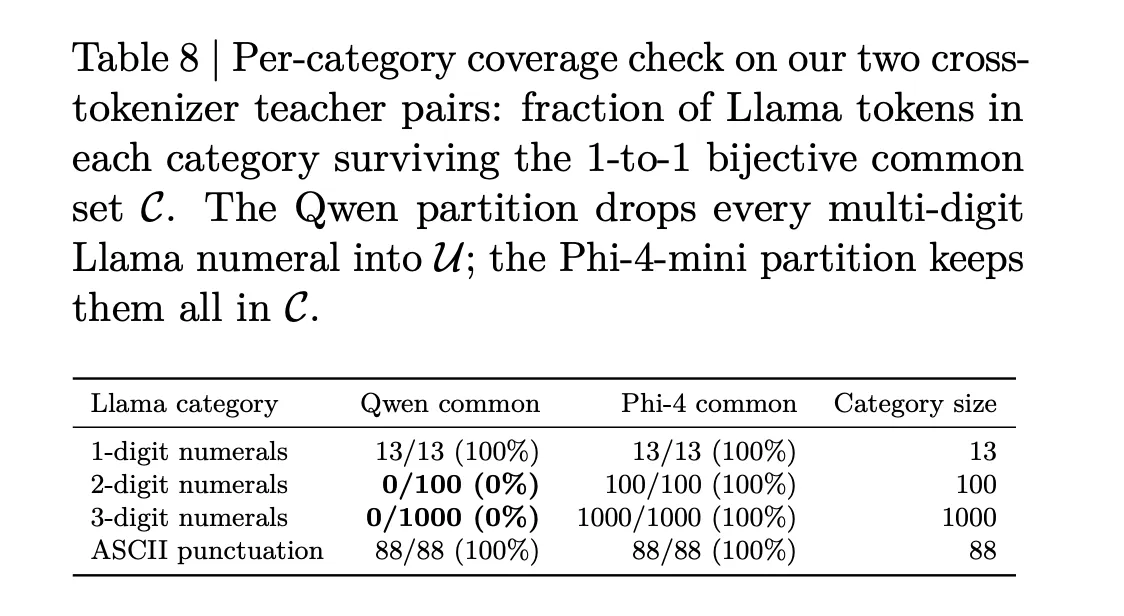
Prior cross‑tokenizer solutions try to sidestep the alignment problem in different ways. Universal Logit Distillation (ULD) rank‑sorts both distributions and minimizes L1 distance, discarding token identity entirely to avoid vocabulary alignment. GOLD, the current state of the art before X‑Token, augments this idea with span alignment and a hybrid loss: it partitions tokens into a 1‑to‑1 string‑matched common subset trained with KL and an uncommon remainder handled with ULD‑style rank matching.
The NVIDIA team identifies structural failures in GOLD that limit its effectiveness. The first highlighted failure — the uncommon‑token failure — occurs when tokenizers fragment text differently and important tokens end up in GOLD’s unmatched uncommon subset, where rank‑based treatment can lose critical identity and ordering information. (The researchers state there is a second structural failure as well.)
X‑Token approaches distillation at the logit‑distribution level to enable cross‑tokenizer KD without requiring auxiliary trainable components or architecture changes: it is described as a drop‑in replacement for the standard KD loss. By operating on logit distributions rather than assuming shared token positions or discarding token identity entirely, the method is intended to allow students to learn from teachers with incompatible tokenizers and to support multi‑teacher distillation across tokenizer families. According to NVIDIA’s reported results, that design yields the cited gains on Llama‑3.2‑1B and the large GSM8k improvement noted above.
Sources
Replies (0)
No replies in this topic yet.