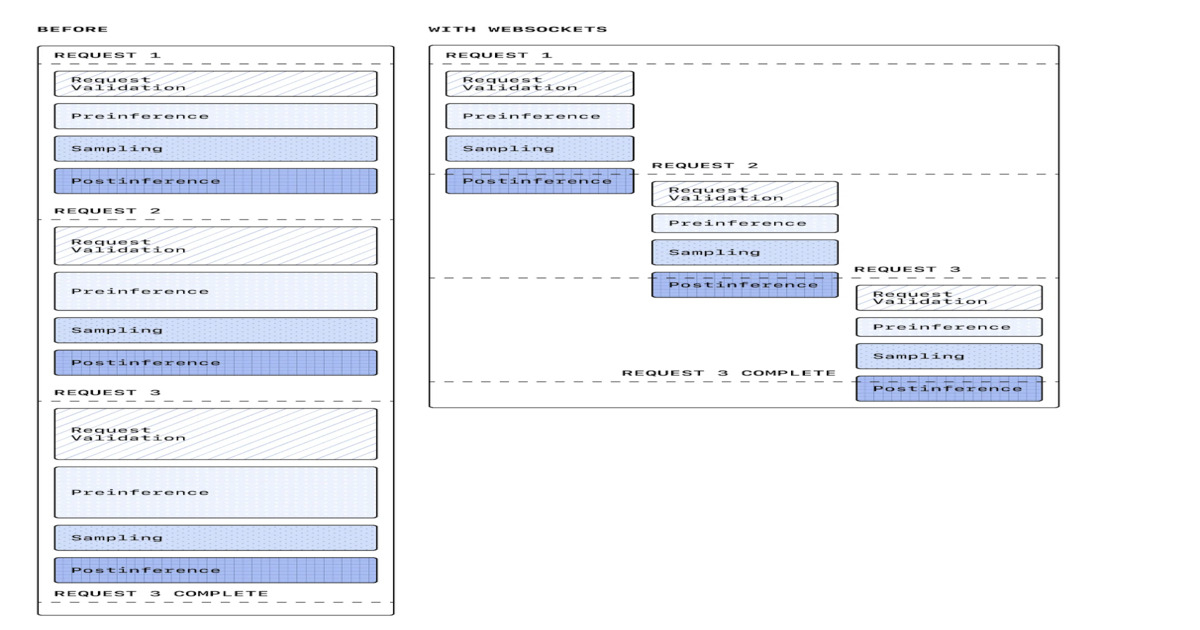
OpenAI has introduced an alpha WebSocket execution mode for its Responses API, replacing repeated HTTP request — response cycles with long‑lived, bidirectional sessions. The change, released after a two‑month partner cycle, reduces handshakes and cold starts by keeping connection state; early production deployments reported end‑to‑end latency reductions of as much as 40%. The mode supports streaming responses, faster tool execution, and more efficient multi‑step orchestration, and engineers can warm up sessions by sending the system prompt and tool definitions first — an approach the company says is compatible with Zero Data Retention (ZDR).
Adoption among developer tooling and coding agent platforms has been rapid. Vercel integrated the WebSocket mode into its AI SDK and reported latency improvements up to 40%; Cline measured a 39% gain in multi‑file workflows; Cursor reported improvements up to 30%. OpenAI also published runtime numbers showing sustained throughput around 1,000 transactions per second and burst capacity near 4,000 TPS in early use cases, indicating the mode can handle the high concurrency and many short steps common to coding agents and real‑time AI systems.
The shift exposes familiar system‑design trade‑offs: as inference speeds have improved, network round‑trip time began to dominate latency budgets for multi‑step agent pipelines. Engineers involved in the rollout described WebSockets as an obvious win for maintaining agent state, but warned that connection lifecycle management, backpressure control and distributed reliability now require explicit handling in production deployments.
For builders, the practical implications are concrete. Replacing multiple HTTP calls with a single persistent session can simplify orchestration and reduce latency; streaming lets clients consume partial outputs during incremental code generation or interactive reasoning; and warming sessions before peak load reduces cold‑start cost. At the same time teams must add operational controls — warm‑up routines, backpressure scaling, and recovery logic — to manage persistent connections at scale. OpenAI says selected partners, including Codex, have already migrated a large share of Responses API traffic to the WebSocket mode, demonstrating early production viability.
Sources
Replies (0)
No replies in this topic yet.