An OpenAI large language model called o1‑preview outperformed physicians on several clinical‑reasoning tasks applied to real emergency‑room records, according to a paper published 30 April in Science. The result highlights potential for LLMs to assist diagnostic and decision‑making steps in acute care, and raises immediate questions about how such models might be integrated into clinical workflows.
The study compared two physicians and two LLMs across diagnostic tasks at multiple stages of emergency‑room care. The research team-which includes Peter G. Brodeur, Thomas A. Buckley and others — evaluated model performance on real cases rather than consumer health Q&A, and the authors recommended further testing of LLMs on real cases with physicians consulted as second opinions at defined checkpoints.

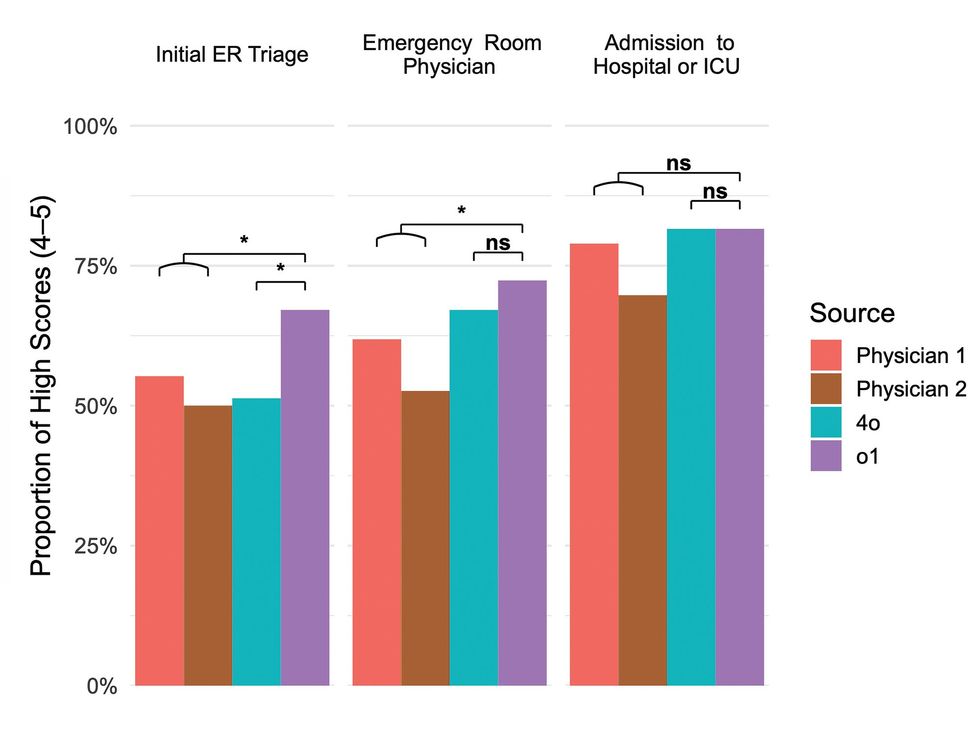
Despite the headline findings, the paper stresses important caveats. Coauthor Arjun Manrai said, “I don’t think our findings mean that AI replaces doctors,” and coauthor Adam Rodman added that he felt “a little queasy about how some of these results might be used,” underscoring that models can appear equally convincing when correct or incorrect. Those cautions sit against mixed broader evidence. Other studies have reported strong diagnostic accuracy in some controlled settings, while different investigations have flagged fabricated citations, flawed clinical advice, and unstable outcomes that depend on scoring methods and evaluation choices.
A separate review found that nearly half of responses from five popular chatbots to open‑ended health questions were flawed, a finding cited by Arya Rao to warn that routine use of these models carries risks that are not yet quantified or mitigated. That review and related work suggest error rates and types vary widely by task and by how performance is measured. The study arrives as clinician‑oriented products reach the market: OpenAI this year released ChatGPT for Clinicians and ChatGPT for Healthcare. Commentators note that newer LLMs or models trained specifically on medical data could perform differently; Mickael Tordjman urged more evidence from prospective clinical trials to validate any real‑world benefit.
For builders and clinicians the practical takeaway is clear: promising laboratory performance does not replace prospective validation and careful workflow design. The authors call for physician‑in‑the‑loop checkpoints, low‑error workflows and further prospective trials to measure benefits and risks, and they warn that hallucinations and confidently stated but incorrect outputs will complicate clinical adoption unless detection and mitigation improve.
Sources
Replies (0)
No replies in this topic yet.