A team from Northwestern University, Tilde Research and the University of Washington unveiled Parallax, a parameterized variant of Local Linear Attention (LLA) that retains standard softmax attention and supplements it with a learned covariance — correction branch. The paper reports improved perplexity at 0.6B and 1.7B model scales and a hardware — friendly increase in arithmetic intensity, outcomes that matter for both model quality and efficient execution on modern accelerators.
Parallax reframes the LLA update as softmax attention plus an additive correction: the layer's output equals the softmax result minus a projected KV covariance term. Rather than performing the original per-query conjugate — gradient solve, Parallax replaces the solver with a learned probe written as ρi = WR xi, where WR is a trainable projection. This formulation keeps the softmax path intact while letting the correction be learned and efficiently executed.
For numerical stability the authors set LLA's boundary amplification factor to zero; with WR = 0 the layer exactly degenerates to standard softmax attention. That property enables a straightforward migration from pretrained Transformers: a checkpoint can be converted by adding WR and fine-tuning, rather than retraining or replacing the attention mechanism entirely.
The paper positions Parallax against prior efficiency work that often seeks to replace softmax attention. LLA upgrades softmax's local — constant (Nadaraya — Watson) estimator to a local — linear estimator with provably smaller integrated mean-squared error, but at scale the original LLA required a per-query CG solve. That solver introduced heavy I/O, a hard regularization — versus-expressiveness tradeoff, and incompatibility with low-precision execution — issues Parallax aims to avoid by learning the probe instead of solving.
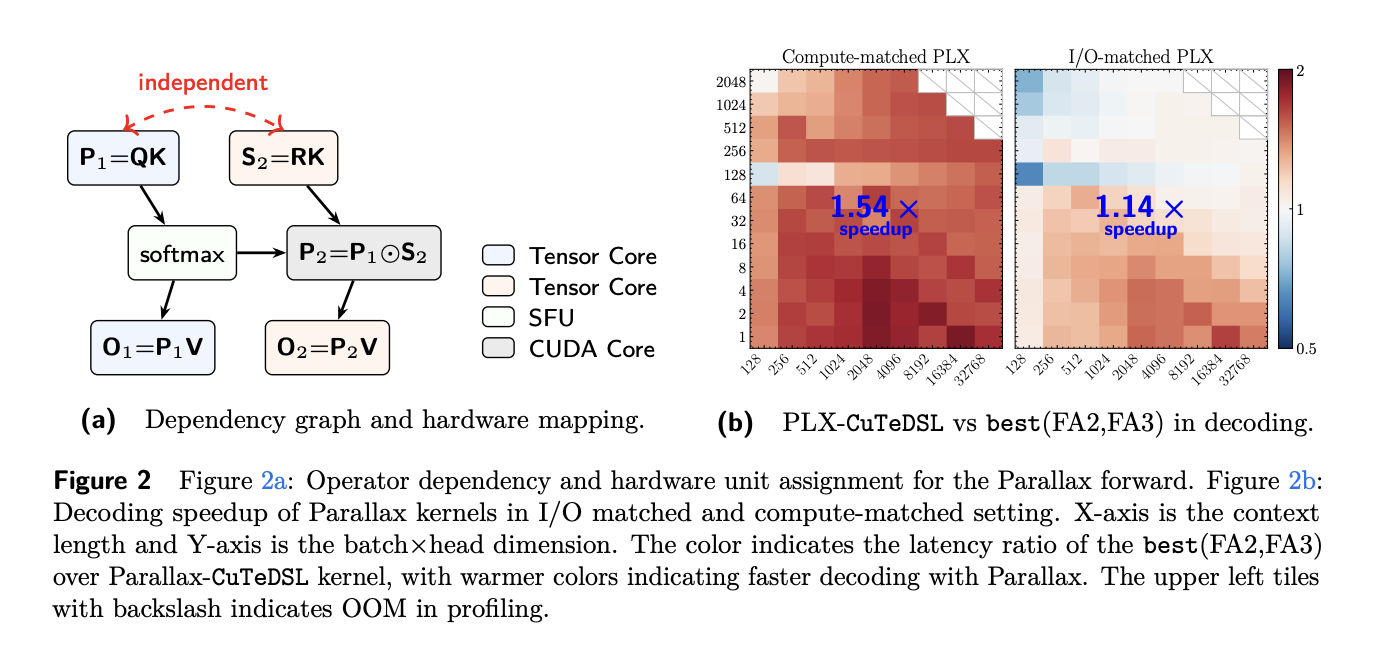
From a systems perspective Parallax preserves FlashAttention's streaming structure and adds a single covariance branch that reuses the same key/value stream, so no extra I/O is required per iteration. By adding compute while reusing memory traffic, Parallax roughly doubles arithmetic intensity in KV-dominated regimes and shifts execution toward compute — bound kernels where optimization yields larger gains. The authors note that Hopper tensor — core matmuls operate on tiles of at least 64 rows and that QK and RK products can be computed jointly within the instructions already emitted by standard attention.
The team profiled a prototype against FlashAttention 2 and 3 on H200 GPUs in BF16 precision, sweeping batch sizes from 1 to 2,048 and context lengths from 128 to 32,768. For builders, Parallax promises easier implementation and low-precision compatibility compared with per-query-solver LLA, plus a simple migration path from pretrained models by adding WR and fine-tuning. The paper also highlights system — level co-design—exampled by Muon-as a practical route to realize the reported performance gains.
Sources
Replies (0)
No replies in this topic yet.