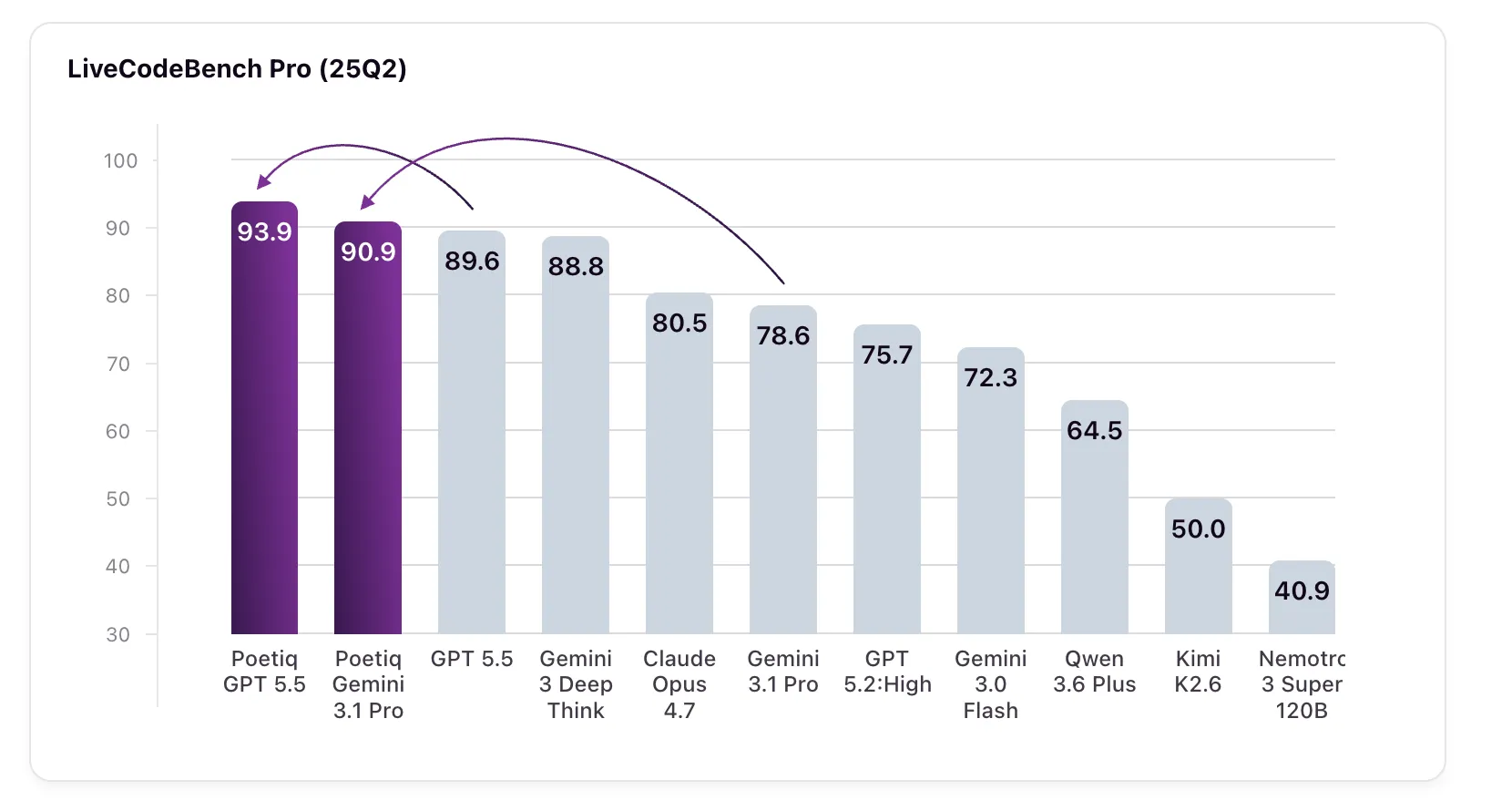
Poetiq says its Meta‑System automatically generated and optimized an inference harness for LiveCodeBench Pro (LCB Pro) using only Gemini 3.1 Pro as the base model, and that the harness materially raised scores for multiple large language models without any model fine‑tuning or access to model internals. This matters because it suggests orchestration and inference engineering alone can improve performance on a competitive coding benchmark where fine‑tuning may be infeasible or costly.
In Poetiq’s reported results, GPT 5.5 High climbed to 93.9% from 89.6% after applying the Meta‑System harness, while Gemini 3.1 Pro-the model used to construct the harness — jumped from 78.6% to 90.9%. Poetiq also reported improvements for Kimi K2.6, Gemini 3.0 Flash, and four additional models; a referenced comparison score for Gemini 3 Deep Think was 88.8%, though that model was not publicly accessible for independent verification.
LiveCodeBench Pro is a competitive coding benchmark focused on C++ tasks sourced from major programming contests. The benchmark withholds public ground‑truth solutions and validates submissions by running them against a comprehensive test harness that enforces runtime and memory constraints; passing requires both correct outputs and adherence to performance limits. The suite is continuously updated and categorizes tasks by human solve rates into Easy, Medium and Hard.
Poetiq framed the work as part of a three‑category evaluation strategy covering reasoning (ARC/AGI), retrieval (Humanity’s Last Exam, HLE) and coding, and set three explicit goals for the coding effort: show an intelligent harness can boost efficacy without fine‑tuning, demonstrate recursive self‑improvement in harness construction, and prove the resulting harness is model‑agnostic and reusable across models. The company defines a harness as the orchestration layer around a model — the way prompts are structured, sequential chains of questioning are formed, outputs are aggregated across multiple calls, and solutions are evaluated against task constraints — and says its Meta‑System generates and iteratively refines those components automatically.
Poetiq notes the Meta‑System borrows insights from its prior ARC and HLE work to address accuracy, runtime and memory simultaneously. For practitioners, the results emphasize that careful inference engineering and orchestration can materially raise coding‑benchmark performance when fine‑tuning is unavailable. some leading models referenced for comparison are not accessible via public API, while the harnessed improvements were demonstrated on the set of models Poetiq could run, pointing to harness optimization as a practical path for teams constrained by model access or tuning budgets.
Sources
Replies (0)
No replies in this topic yet.