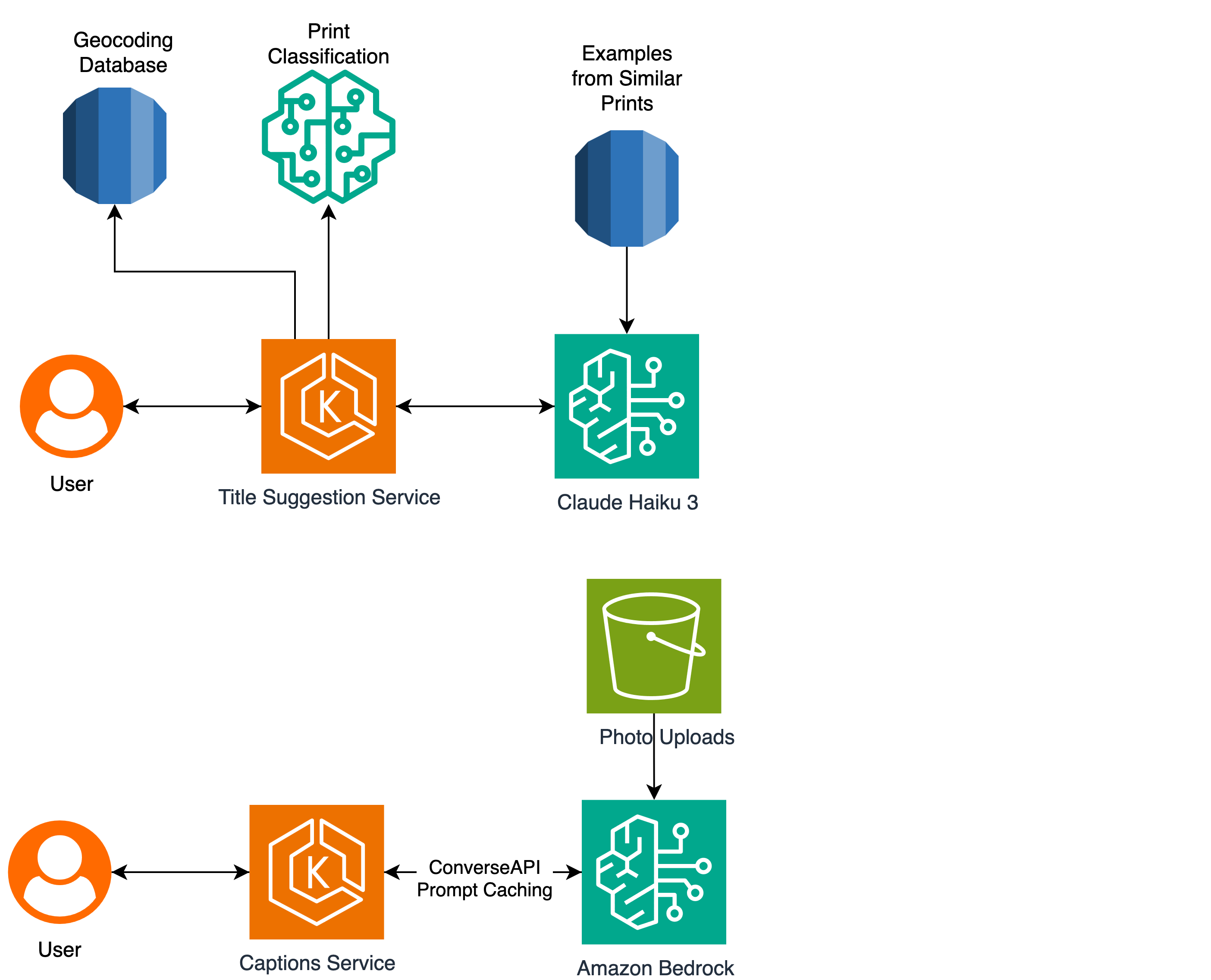
Popsa, a global technology company specializing in automated photo book creation across 50 countries, has completely overhauled its user-facing title generation feature by integrating advanced generative artificial intelligence. Moving away from a rigid, legacy rules — based system introduced in 2021, the company deployed a sophisticated AI pipeline through Amazon Bedrock. This upgraded infrastructure utilizes Amazon Nova Lite, Nova Pro, and Anthropic’s Claude 3 Haiku to automatically generate creative, brand — aligned titles and subtitles in 12 distinct languages.
In the highly competitive personalized print industry, consumer friction frequently arises at the final customization stage when users first view their front cover. Historically, users who lack innate copywriting skills or the time to craft compelling captions often default to generic, uninspired labels such as France 2024 or simply Photos. Popsa's original Title Suggestion Graph algorithm attempted to solve this by extracting device metadata, like timestamps and geocoordinates, alongside on-device computer vision features identifying subjects such as a beach or a pet, but it relied heavily on static templates rather than fluid creativity.
To resolve this friction and inspire more engaging designs, the revamped backend relies on a retrieval — augmented generation approach orchestrated through a unified application programming interface. The technical process begins when a new photo book is compiled; the system retrieves similar past designs and acceptable titles from a dedicated database. Using few-shot prompting, these examples are seeded into the conversation prior to appending the user’s new document, allowing the deployed models to generate contextually relevant, highly personalized text options.
Given the immutable nature of printed media and specific layout restrictions, ensuring the absolute reliability of this multi — model architecture was paramount. Popsa engineered a rigorous automated evaluation pipeline utilizing a curated dataset of over 100 historical photo book designs to test strict formatting requirements. Every AI output must return as a valid JSON object containing specific keys for title, subtitle, and category, while strictly adhering to a 36 — character limit per line to prevent text cutoff on the physical printed cover.
Beyond technical parsing, the generated text needed to align with Popsa's distinct brand voice and ensure cohesion between the main title and its accompanying subtitle. Categories assigned to the text must also be perfectly accurate, as they trigger specific visual icons rendered in the mobile application; an imagined or incorrect category prevents the icon from appearing entirely. To rapidly test these broader guidelines, including theme consistency and multilingual quality, the engineering team employed an LLM-as-a-judge framework, iterating through various prompts and methods before settling on the optimal retrieval — based strategy.
The transition to this dynamically orchestrated pipeline has already driven robust and measurable business outcomes for the technology firm. From an operational standpoint, the engineering team reported notably faster API response times and a significant reduction in ongoing computational expenditures compared to earlier iterations of the feature. Furthermore, the higher quality of copy has resulted in documented uplifts in both user engagement and actual purchase rates, successfully generating over 5.5 million personalized photo book titles in 2025 alone.
Sources
Replies (0)
No replies in this topic yet.