A state — of-the-art snippet generator built around a query — aware context compression model was deployed this month to the applications and API Platform. For each user query and each candidate search result the module selects a minimal set of spans from source pages to serve as evidence before invoking downstream models or agents, producing extractive snippets that shrink input tokens while preserving original wording and citation alignment. Builders and API users should see faster inference and lower per-request costs as a result.
Raw retrieved context is often noisy: pages mix needed evidence with navigation text, headers and footers, ads, metadata and other distractors. The write — up identifies three concrete harms from passing that raw context to LLMs: reduced accuracy through “context rot,” higher latency because models must process more tokens during reasoning, and greater serving cost as both input and reasoning token counts rise.
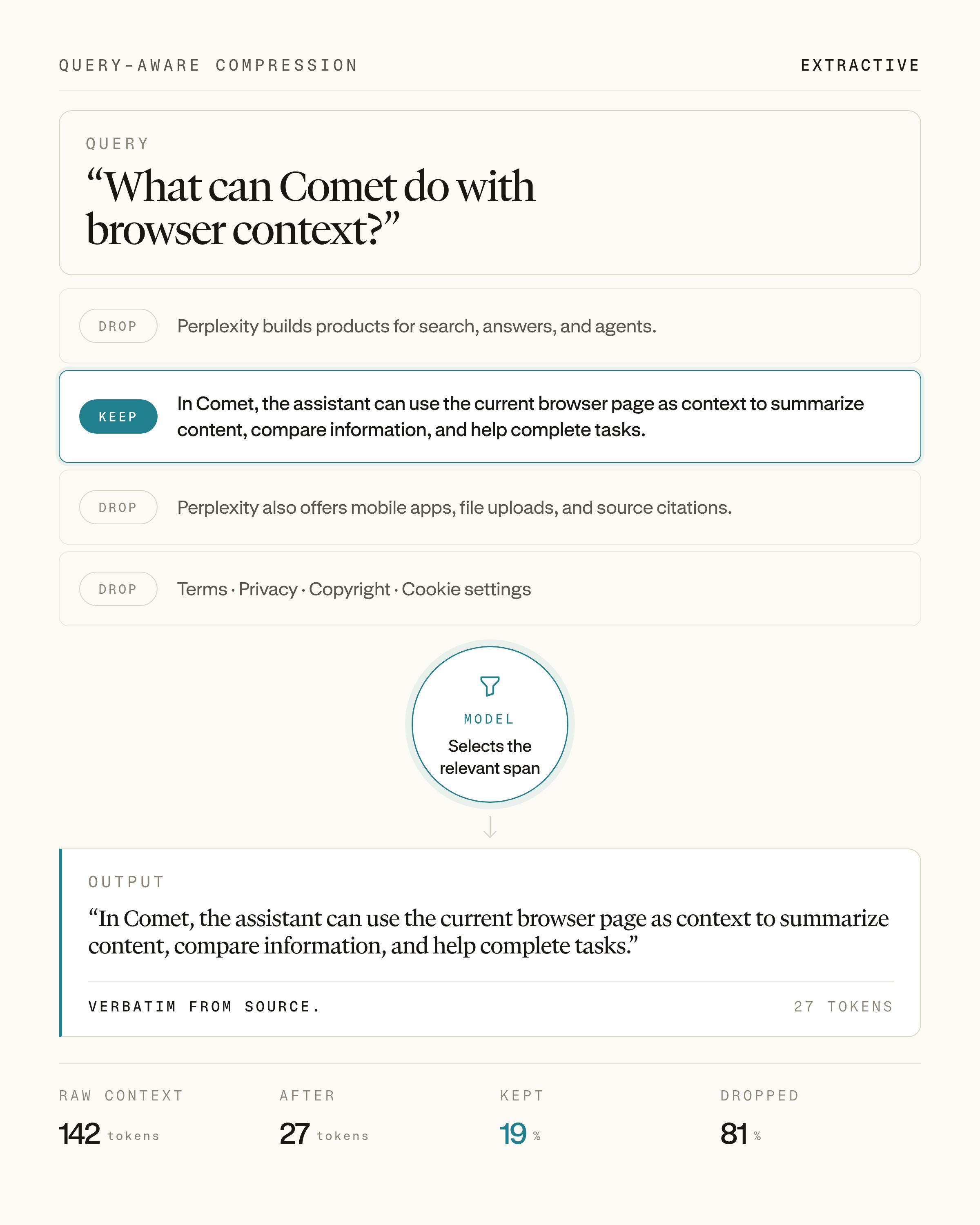
The team framed snippet generation as an extractive context — compression task rather than as generative summarization. Generated, query — focused summaries can paraphrase or introduce wording not present in the source, weakening citation fidelity and adding latency and cost; the extractive approach returns surgical extracts (spans) to keep evidence grounded in the original text while trimming unnecessary tokens. The deployment is described as part of a broader investment in improving context precision across the platform. The write — up classifies snippet methods into selection — based and generation — based families, defines the input/output schema for the compression task, and outlines training and evaluation priorities intended to deliver best-in-class performance on this evidence — selection problem.
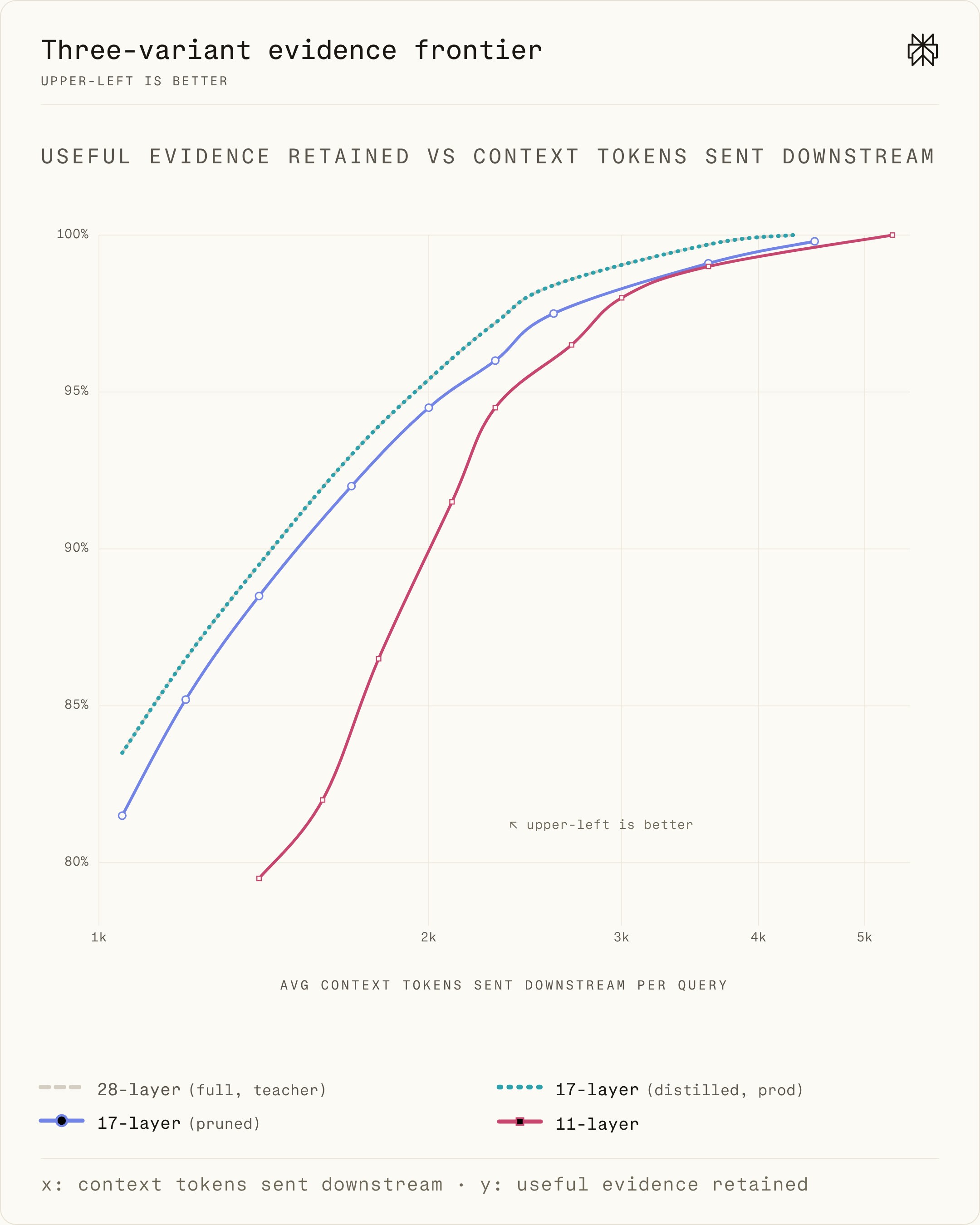
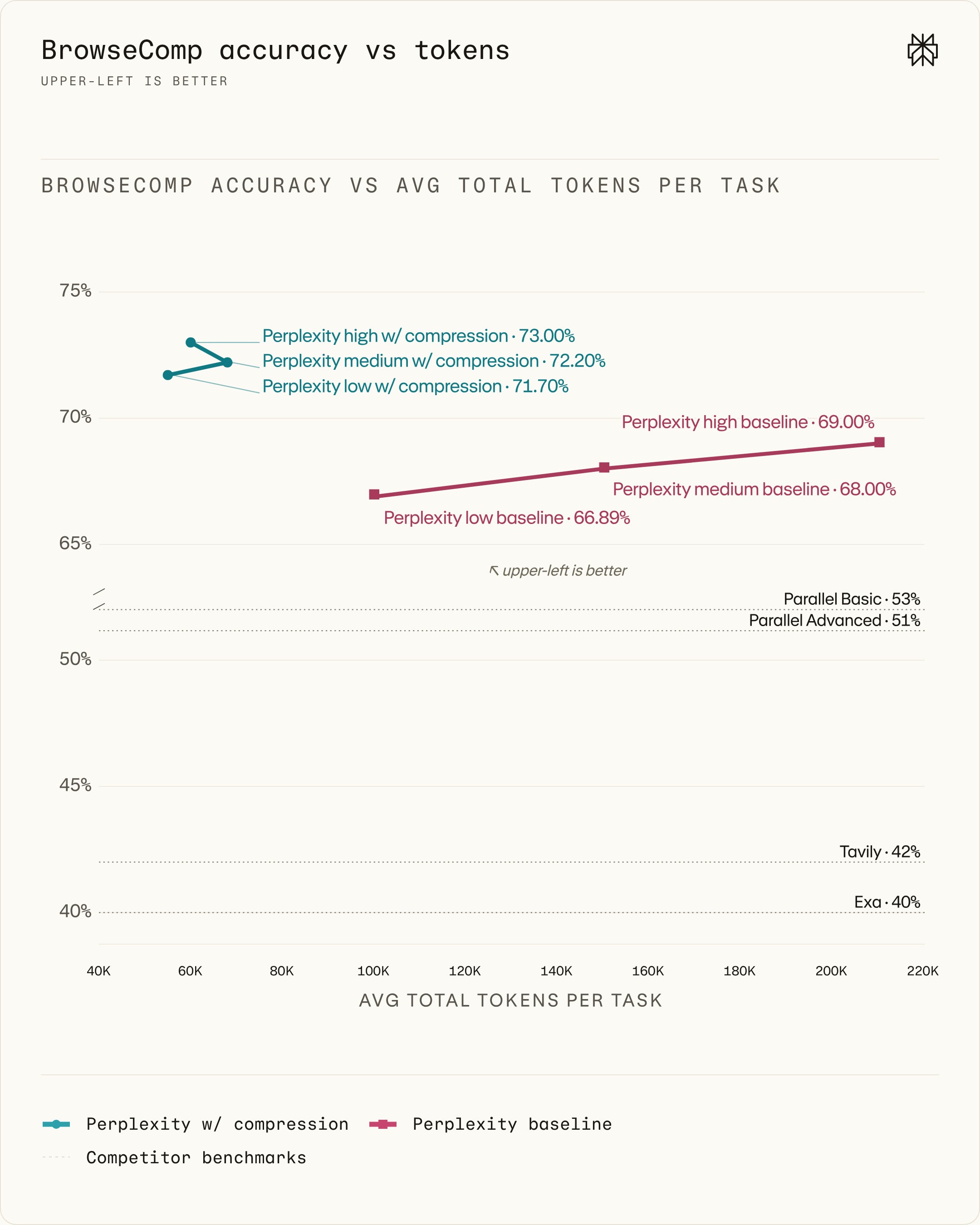
For implementers the implications are practical: downstream agents receive smaller, more precise evidence windows that should improve grounding, lower inference latency, and reduce per-request token costs. The article recommends treating the evidence layer as extractive and query — aware to avoid the tracing and cost pitfalls associated with on-the-fly summarization.
Sources
Replies (0)
No replies in this topic yet.