At the Alibaba Cloud Summit on May 20, the Qwen team unveiled Qwen3.7‑Max, a closed‑weight, text‑only reasoning agent designed for sustained, autonomous multi‑step execution across coding, debugging and workflow automation. The model’s 1,000,000‑token context window and agentic features are intended to let it manage long‑horizon tasks that may span hundreds or thousands of steps, and Alibaba said API access will be provided for the newly announced flagship.
Qwen3.7‑Max emphasizes an extended “thinking” mode: it generates an internal chain‑of‑thought sequence — planning, checks and corrections — before producing a final answer, and that internal trace can be exposed in Qwen Chat. The team positions this behavior as a means to improve stepwise reasoning and agentic decision making for complex workflows without exposing internal weights.
Two preview variants surfaced prior to the formal announcement on Arena AI/LM Arena: Qwen3.7‑Max‑Preview and Qwen3.7‑Plus‑Preview. In Arena rankings Max‑Preview reached #13 in the Text Arena while Plus‑Preview hit #16 in the Vision Arena; Alibaba’s lab as a whole ranked #6 in text and #5 in vision. Qwen3.7‑Plus is described separately as a balanced, multimodal reasoning build with a toolchain that Alibaba says will open gradually.
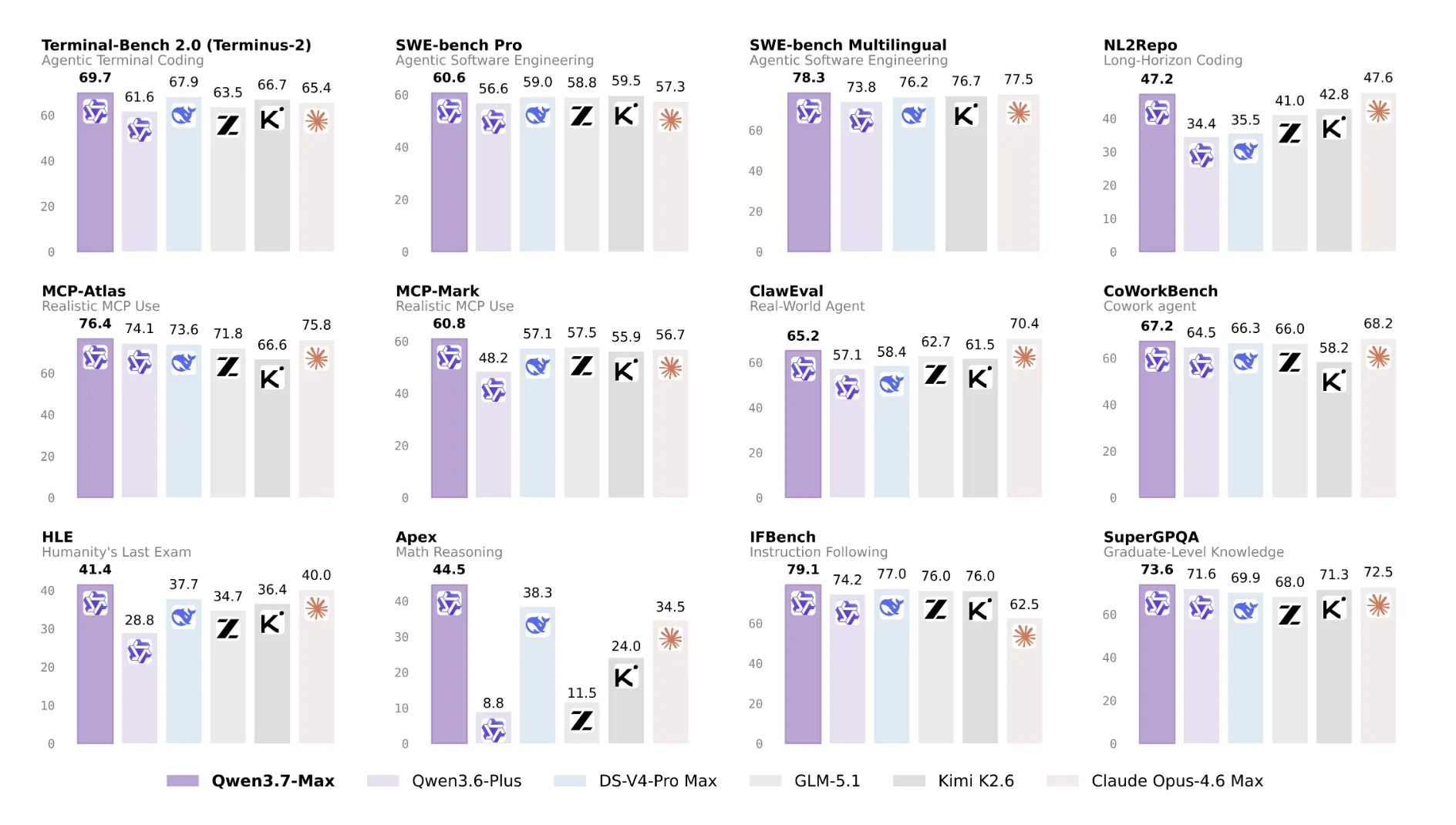
On the Artificial Analysis Intelligence Index v4.0, Qwen3.7‑Max scored 56.6, placing fifth overall and improving 4.8 points over the Qwen3.6 Max Preview result of 51.8. That score places Qwen3.7‑Max ahead of Google’s Gemini 3.5 Flash (55.3) but below GPT‑5.5 (60.2), Claude Opus 4.7 (57.3) and Gemini 3.1 Pro Preview (57.2). The Index aggregates ten evaluations, including SciCode, Terminal‑Bench Hard and GDPval‑AA.
Most of Qwen3.7‑Max’s Index gains concentrated in scientific reasoning, agentic capability and coding tests: CritPt rose 9.7 percentage points (from 3.7% to 13.4%), Humanity’s Last Exam increased 9.2 points (28.9% to 38.1%), Terminal‑Bench Hard climbed 6.9 points (43.9% to 50.8%), and GDPval‑AA added 42 Elo (1,504 to 1,546). In the Intelligence Index run the model generated roughly 97 million tokens compared with an average of about 24 million tokens for the other evaluated models.
The 1,000,000‑token context window substantially expands capacity over the prior Qwen3.6 Max Preview’s 256K window, enabling a single request to contain a mid‑sized code repository or a large stack of documents. Alibaba has not announced pricing or independent long‑context reliability test results; as a point of reference, Qwen3.6 Max Preview was previously priced at $1.30/$7.80 per million input/output tokens on Alibaba Cloud.
Sources
Replies (0)
No replies in this topic yet.