A multi‑institution research team has proposed MEMO, a modular framework that internalizes new facts in a separate, trainable MEMORY model so frozen large language models (LLMs) can access updated knowledge without altering their weights. The approach promises a way to refresh model knowledge while avoiding the cost and instability of continual pretraining or fine‑tuning the primary reasoning model.
MEMO splits responsibility between a small, trainable MEMORY and an EXECUTIVE reasoning model that remains frozen and is treated as a black box. In the paper’s experiments, the MEMORY model is Qwen2.5‑14B‑Instruct, while EXECUTIVE models tested include Qwen2.5‑32B‑Instruct and Google’s Gemini‑3‑Flash. MEMO interacts with the EXECUTIVE via only standard I/O and does not require access to the EXECUTIVE’s weights or logits.
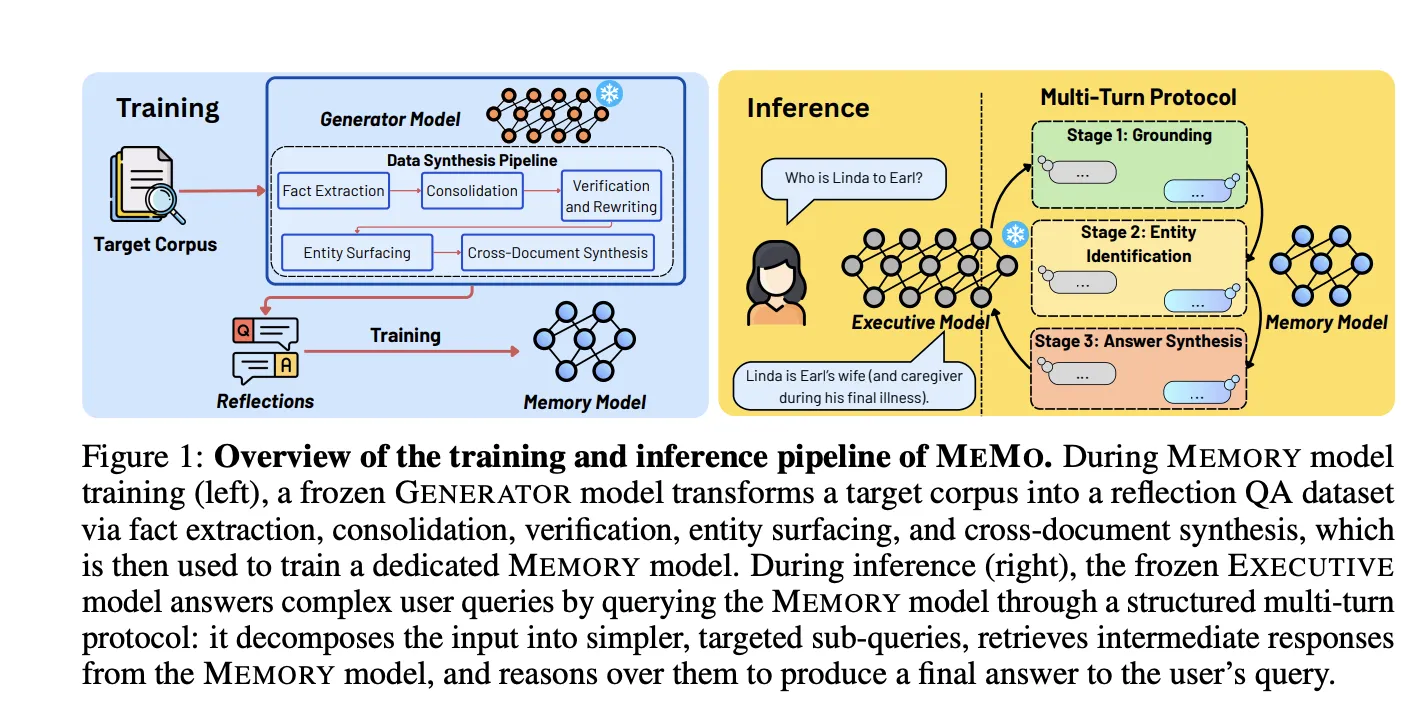
Training the MEMORY begins with a five‑step data synthesis pipeline driven by a GENERATOR (in the experiments Qwen2.5‑32B‑Instruct). The pipeline converts raw documents into a reflection QA dataset through: fact extraction; consolidation of related facts; verification and rewriting to form self‑contained QA pairs; entity surfacing to reverse attribute/identity mappings; and cross‑document synthesis to produce multi‑document reasoning QA pairs.
Cross‑document synthesis proved crucial: an ablation that removed this step reduced accuracy on NarrativeQA from 24.00% to 6.37%, showing it is the dominant contributor to final training data quality and downstream performance. After synthesis, the MEMORY is trained by supervised fine‑tuning with loss computed only over answer tokens; at inference the MEMORY must respond from internalized parametric knowledge and is not given the original source documents.
At query time the EXECUTIVE drives a structured, multi‑turn protocol in sequential stages. Stage 1, Grounding, decomposes a user query into atomic subquestions that MEMORY answers independently. Stage 2, Entity identification, uses those grounding replies to issue targeted follow‑ups and iteratively narrow candidate entities. This controlled interaction is designed to enable cross‑document reasoning through the MEMORY interface, letting the frozen EXECUTIVE leverage synthesized parametric knowledge instead of relying on runtime retrieval.
The paper contrasts MEMO with existing options: non‑parametric retrieval‑augmented methods can suffer from retrieval noise and weak cross‑document reasoning; parametric continual pretraining or fine‑tuning is costly and risks catastrophic forgetting; and latent memory approaches create representation coupling that limits portability. MEMO’s decoupling of memory and reasoning aims to avoid these downsides and to support closed‑source EXECUTIVE models, but the authors note the approach depends on a high‑quality generator and a robust QA synthesis pipeline to be effective.
Sources
Replies (0)
No replies in this topic yet.