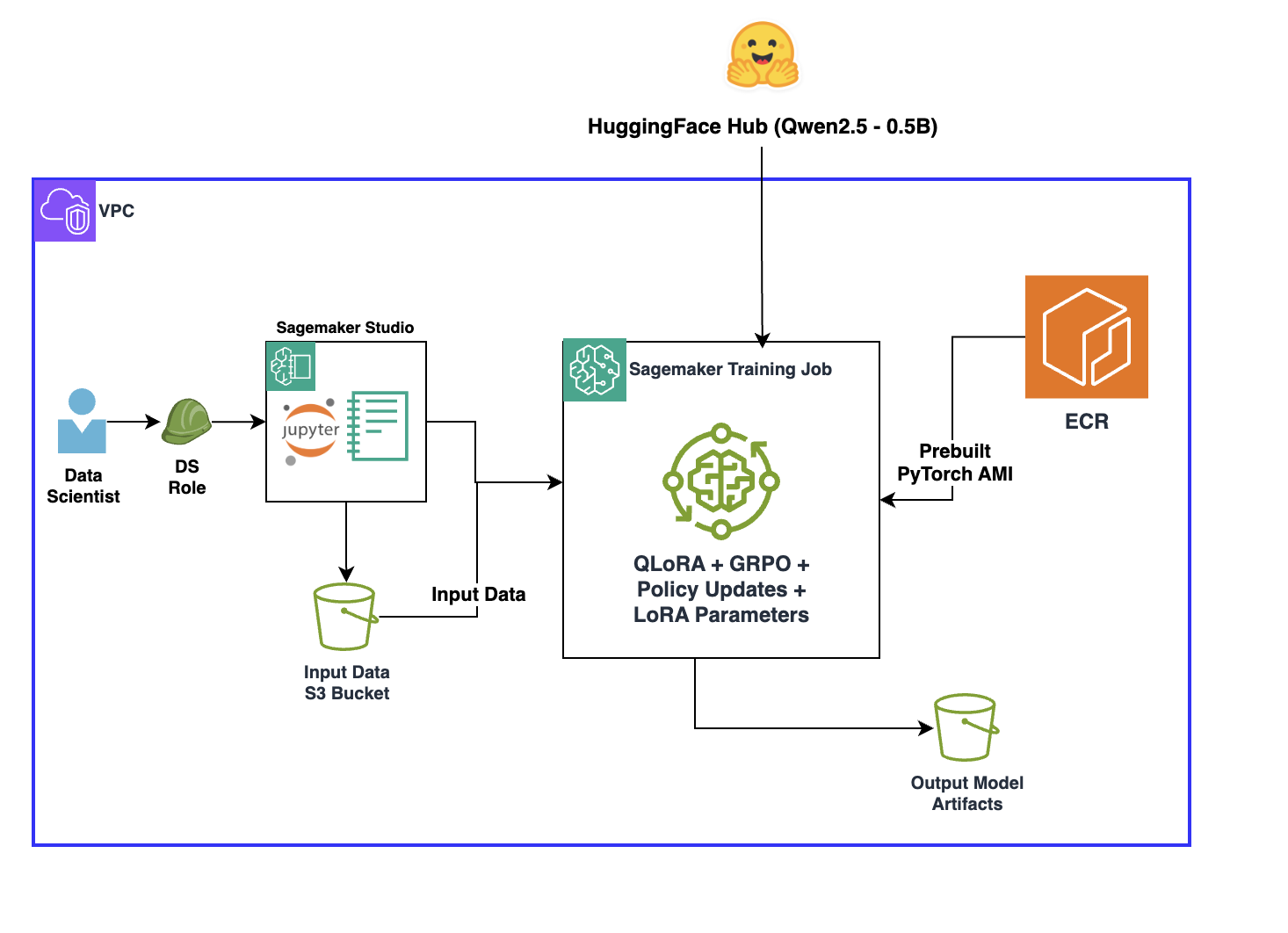
A technical post presents an implementation of reinforcement learning with verifiable rewards (RLVR) on SageMaker AI that aims to make reward signals more transparent and reliable during model training. The authors demonstrate the approach on the GSM8K (Grade School Math 8K) dataset and report improved math problem‑solving accuracy; by replacing subjective scoring with programmatic checks, the method is intended to reduce dependence on human labels and accelerate iteration for tasks with verifiable outputs.
RLVR frames rewards as rule‑based, programmatic functions that automatically score model outputs against explicit correctness criteria. Rather than relying primarily on human ratings, these deterministic reward functions evaluate outputs against defined rules, providing objective, reproducible feedback that can directly guide policy updates during reinforcement learning.
To strengthen learning, the implementation layers Group Relative Policy Optimization (GRPO) and incorporates few‑shot examples alongside the verifiable reward functions. GRPO structures updates across groups of policies to improve stability, while few‑shot examples give the model short demonstrations of desired behavior; together they are used in the SageMaker AI pipeline to refine policies and enhance performance on GSM8K.
Sources
Replies (0)
No replies in this topic yet.