Sakana AI and NVIDIA report that simple L1 regularization can drive feedforward layer activations to over 99% sparsity with negligible downstream accuracy loss, and that this extreme activation sparsity can be converted into concrete GPU performance improvements. The work targets the costly feedforward blocks in large language models and shows how matching sparse representation and kernel design to GPU hardware can reduce both FLOPs and memory bandwidth.
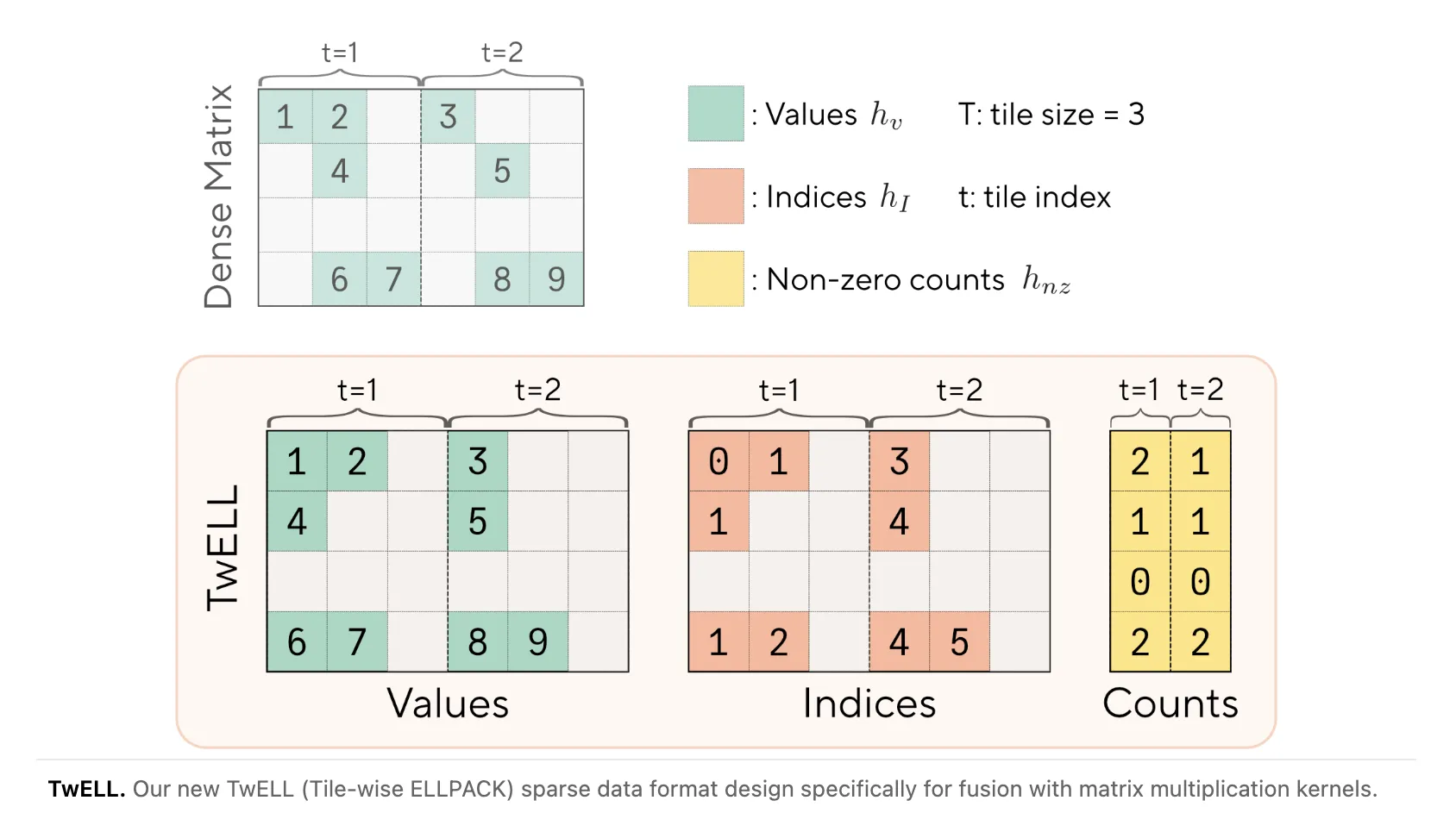
The team’s TwELL format and fused CUDA kernels are built around GPU matmul tile behavior. TwELL partitions columns into horizontal tiles that match the matmul tile size and packs nonzero values locally inside each tile during the kernel epilogue. That packing avoids a separate conversion kernel or an extra global memory pass, keeping sparse data layout work inside the kernel and reducing overheads that usually cancel theoretical savings.
For inference the authors implement a single fused kernel that reads gate activations in TwELL, performs the up and down projections together, and never writes the intermediate hidden state back to global memory. By fusing these steps and operating directly on the tile-packed sparse format, the inference path avoids extra synchronization and memory traffic that would otherwise erode speed gains.
On the training side the paper uses a hybrid sparse layout that dynamically routes rows into a compact ELL-like matrix for sparse rows while maintaining a dense backup for overflow rows. That hybrid approach addresses highly non-uniform sparsity observed during training, where the maximum nonzeros per row can be orders of magnitude larger than the average and can otherwise produce brittle performance cliffs.
This work focuses explicitly on the harder, high-throughput regime of batched GEMM with thousands of tokens rather than the single — token, memory — bound GEMV setting targeted by earlier sparse LLM kernels such as TurboSparse, ProSparse and Q — Sparse. Modern NVIDIA GPUs are optimized for dense Tensor Core matmuls with large tiles, so exploiting activation sparsity in the compute — bound batched setting required a sparse format and kernels that align with GPU tile behavior.
Measured end-to-end gains reported in the paper include roughly a 20.5% inference speedup and about a 21.9% training speedup. Those improvements arise from reduced DRAM traffic and fewer compute operations inside feedforward blocks; the TwELL epilogue construction and fused inference kernel are cited as key to avoiding the conversion and synchronization overheads that nullified savings in older ELLPACK — style approaches.
The results appear in arXiv:2603.23198 and were presented at ICML 2026. For practitioners the paper offers a concrete recipe: apply L1 regularization to induce high activation sparsity, adopt a tile-aware sparse format like TwELL, and use fused CUDA kernels designed around matmul tiles to capture feedforward FLOP and memory — bandwidth savings in both training and high-throughput inference on modern GPUs.
Sources
Replies (0)
No replies in this topic yet.