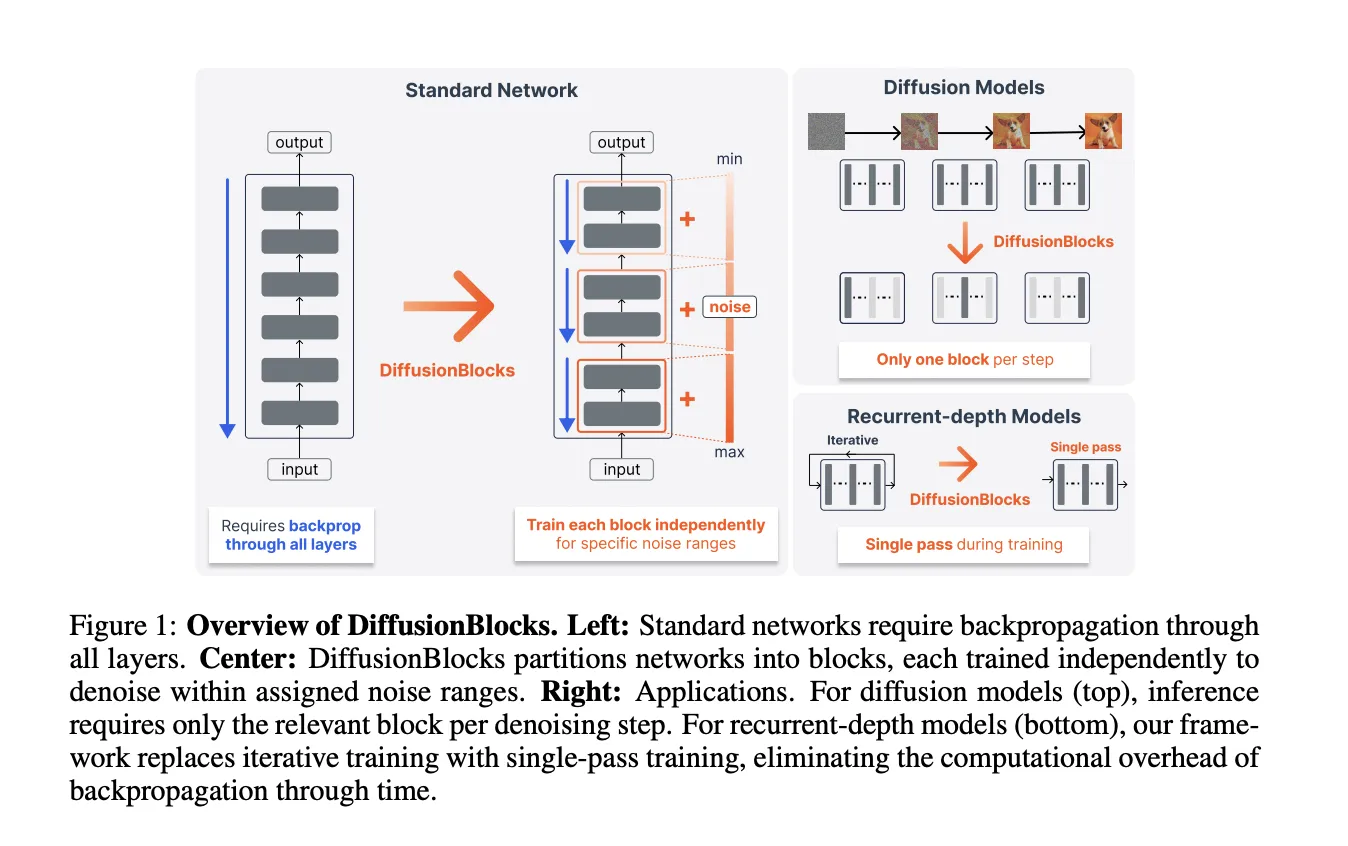
Sakana AI and University of Tokyo researchers have proposed DiffusionBlocks, a block‑wise training framework that treats residual network updates as denoising steps, and the approach promises substantial peak‑memory savings during training. The paper, available on arXiv (2506.14202), shows how stacking residual blocks can be interpreted as Euler discretizations of the reverse process in score‑based diffusion models, which justifies training each block as a local denoiser. This reframing matters because it enables per‑block optimization without full end‑to‑end backpropagation, reducing the memory bottleneck that limits scaling.
The method converts a standard L‑layer residual network into a block structure with three concrete modifications. First, the network is partitioned into B contiguous blocks. Second, each block is assigned a subinterval of a global noise range [σ_min, σ_max], with noise samples drawn from a recommended log‑normal p_noise. Third, each block’s input is noise‑conditioned and equipped with AdaLN (adaptive layer normalization) plus a local objective: the block predicts the clean target from its noisy input.
Training proceeds by sampling a single block per iteration, so only that block’s activations and computations are active during the update. This design limits activation storage to the block being trained and confines optimizer state updates to the same subset of parameters, which contrasts with standard end‑to‑end training where activations and optimizer states for all layers must be held concurrently.
DiffusionBlocks targets a core scaling bottleneck: end‑to‑end backpropagation requires storing activations across all layers and, with optimizers like Adam, each layer also consumes memory for parameters, gradients and the optimizer’s two state tensors (moment and variance), effectively about 4× parameter size per layer. Existing mitigations such as activation checkpointing reduce activation memory but do not lower optimizer/state memory. By partitioning the network into B independently trained blocks, DiffusionBlocks reduces peak memory roughly by a factor of B.
Theoretical grounding links residual updates to the probability‑flow ODE used in score‑based diffusion modeling. The paper cites the reverse process d z_σ / dσ = −σ ∇_z log p_σ(z_σ) and demonstrates that an Euler discretization of this ODE produces an update rule structurally identical to the residual connection z_l = z_{l-1} + f_θ_l(z_{l-1}). That correspondence motivates treating each residual block as a denoising step and optimizing a local score‑matching loss at the block’s assigned noise level without inter‑block communication during training.
To balance denoising difficulty across blocks, the authors recommend partitioning the noise range so each block receives exactly 1/B of p_noise’s probability mass (equi‑probability partitioning) rather than equal σ intervals. With the proposed log‑normal training distribution, intermediate noise levels contribute most to generation quality, so equi‑probability splits distribute learning difficulty more evenly and improve empirical results compared with naive splits.
Sources
Replies (0)
No replies in this topic yet.